 Data Engineering
Data Engineering  Data Strategy + Governance
Data Strategy + Governance  Data Migrations
Data Migrations  Concierge + Support
Concierge + Support  Artificial Intelligence
Artificial Intelligence  Training + Enablement
Training + Enablement  Data Analytics + Insights
Data Analytics + Insights  Financial Services
Financial Services  Communications, Media + Entertainment
Communications, Media + Entertainment  Healthcare + Life Sciences
Healthcare + Life Sciences  Technology + Digital Natives
Technology + Digital Natives  Manufacturing + Automotive
Manufacturing + Automotive  Public Sector
Public Sector  Retail + Consumer Goods
Retail + Consumer Goods  Race to the Lakehouse
Race to the Lakehouse  AI + Data Maturity Assessment
AI + Data Maturity Assessment  Unity Catalog
Unity Catalog  Rapid GenAI
Rapid GenAI  Modern Data Connectivity
Modern Data Connectivity  Gatehouse Security
Gatehouse Security  Health Check
Health Check  Sample Use Case Library
Sample Use Case Library  Blog
Blog  Events
Events  About Us
About Us  Careers
Careers  Founding Team
Founding Team 
Monitoring ML Models in Production with Databricks
Most ML models do not break in development. They break quietly in production, when data changes, performance drifts, and no one notices until business trust is already slipping. That is why monitoring is not an afterthought. It is one of the foundations of enterprise AI.

True CI/CD for the Lakehouse: Infrastructure as Code (IaC) & DABs
There is a conversation I have had more times than I can count. A client tells me their team “already has CI/CD.” When I ask them to walk me through it, the answer usually sounds like this: a developer runs a notebook to completion, exports it, uploads it to a shared folder, and notifies the production team via Slack to “pull the latest version.” That is not CI/CD. That is a deployment ceremony wrapped in good intentions.
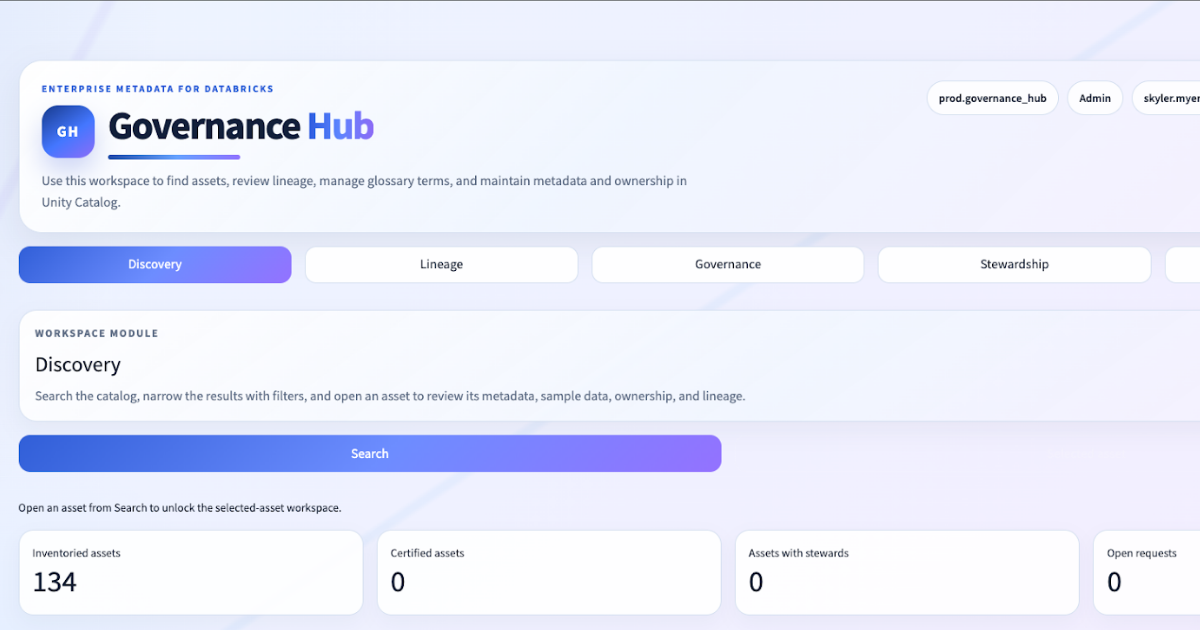
The Next Generation Data Governance Experience In Databricks
At Entrada, we spend a lot of time in environments where the governance conversation sounds the same.
The client already has Databricks. They already have Unity Catalog. They already have tables, schemas, comments, tags, and lineage. What they do not have is a governance operating surface that feels like a true metadata product: search-first discovery, entity-centric governance workflows, opinionated lineage workspaces, stewardship controls, and a place where governance activity actually happens.

Hidden Compute Costs in Enterprise Migrations: Why Execution Model Matters
Your Databricks migration pipeline is likely paying more for cluster lifecycle overhead than for actual data processing. That hidden penalty – the latency tax – emerges when every notebook invocation spins up its own cluster from scratch.

From DAX Filters to Data Contracts: Migrating Power BI Security to Unity Catalog
The security review took longer than the migration itself. I was auditing a client’s Power BI environment: 47 static RLS roles, each with its own DAX filter expression, each maintained by a different team, none of them connected to the data layer. When an analyst queried the same tables directly from a notebook, the filters simply didn’t apply. Two security models, one dataset, zero consistency.

Containerizing the Lakehouse: The Role of Kubernetes in Modern Data Platforms
Data engineering teams spend enormous energy building reliable pipelines – clean medallion layers, solid transformation logic, well-tuned Spark jobs. Then something breaks in production that worked perfectly in development. A library version changed. An environment variable was missing. A Spark executor launched with a subtly different runtime than the one the job was built against.

Advanced Unity Catalog Strategy: Multi-Cloud Federation
Imagine this scenario: a client has over 1,000 tables in an on-premise data warehouse. Some tables are extremely wide, with up to 500 columns, and contain millions of records. If any of these tables fell into the wrong hands, it could cause serious problems.

Building a Bonafide Business Glossary in Databricks with Apps, Lakebase, and Unity Catalog
For years, the Business Glossary has been the elusive holy grail of Data Governance. Organizations have spent millions on legacy platforms like IBM Knowledge Catalog (IKC) to define their business terms, hierarchies, and stewardships. These tools offer rich semantic layers but suffer from a fatal flaw: they are siloed from the actual data.

From Telemetry to Triumph: Using a Unified Lakehouse to Train and Deploy AI for Formula 1 Performance Optimization
When I work with high performance teams, whether in motorsport or enterprise, I see the same pattern: data is not the advantage. The advantage is the ability to turn data into decisions that are fast, trustworthy, and repeatable.

Beyond 2025: The Strategic Shift from “Data Pipelines” to “Data Products”
Modern data teams are surrounded by success signals that no longer mean very much. Dashboards show pipelines running on schedule. Jobs complete within SLAs. Infrastructure metrics glow green. And yet, business stakeholders still don’t trust the numbers.