Data Engineering
Data Engineering  Data Strategy + Governance
Data Strategy + Governance  Data Migrations
Data Migrations  Concierge + Support
Concierge + Support  Artificial Intelligence
Artificial Intelligence  Training + Enablement
Training + Enablement  Data Analytics + Insights
Data Analytics + Insights  Financial Services
Financial Services  Communications, Media + Entertainment
Communications, Media + Entertainment  Healthcare + Life Sciences
Healthcare + Life Sciences  Technology + Digital Natives
Technology + Digital Natives  Manufacturing + Automotive
Manufacturing + Automotive  Public Sector
Public Sector  Retail + Consumer Goods
Retail + Consumer Goods  Race to the Lakehouse
Race to the Lakehouse  AI + Data Maturity Assessment
AI + Data Maturity Assessment  Unity Catalog
Unity Catalog  Rapid GenAI
Rapid GenAI  Modern Data Connectivity
Modern Data Connectivity  Gatehouse Security
Gatehouse Security  Health Check
Health Check  Sample Use Case Library
Sample Use Case Library  Blog
Blog  Events
Events  About Us
About Us  Careers
Careers  Founding Team
Founding Team 
Formula 1 is the perfect example. Telemetry arrives in huge volume, in many formats, and under constant change. Add simulation outputs, weather, track evolution, and operational logs, and you get an environment where Databricks Lakehouse AI can deliver real gains, but only if the foundation is unified, governed, and built for production.
Why telemetry alone does not win races
Telemetry is valuable because it is close to reality, but it is also noisy, context dependent, and easy to misinterpret. A model that looks great in a notebook can fail on race day for one simple reason: the organization cannot reliably reproduce how the data was prepared, which features were used, which assumptions were made, and which model version is running.
That is why I push for a unified Lakehouse architecture. It brings data engineering, analytics, and machine learning into one governed system so teams stop negotiating the numbers and start acting on them.
The Lakehouse blueprint for performance optimization AI
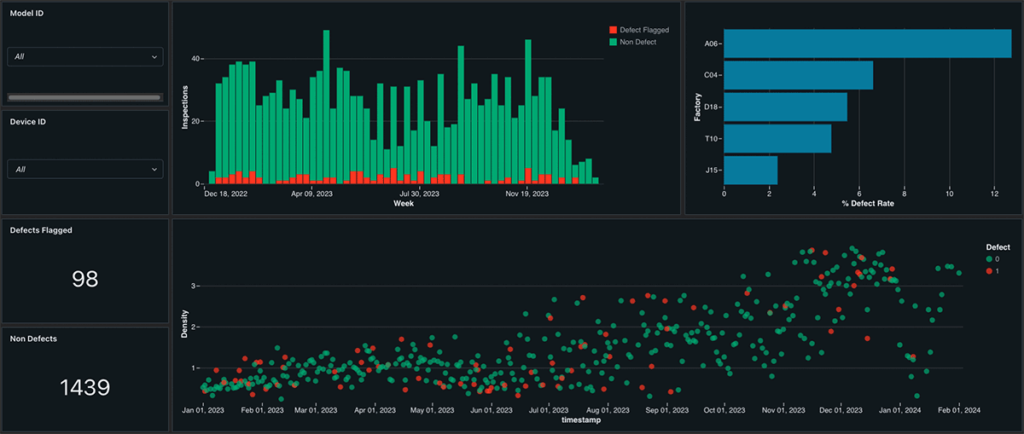
1) Ingest and standardize telemetry at scale
Source: https://www.databricks.com/blog/iot-time-series-analysis
The ingestion layer must handle both streaming and incremental loads, while staying resilient to schema changes. The goal is simple: land telemetry into reliable tables quickly, then standardize timing, units, and event semantics so downstream work is consistent. This is where many teams either build long term speed, or long term technical debt.
2) Build features that stay consistent across race conditions
Source: https://www.databricks.com/de/product/machine-learning/lakehouse-monitoring
Performance optimization models often depend on features such as tire degradation signals, energy deployment efficiency, braking stability, thermal windows, and stint progression context. The best practice is to treat these features like products: versioned, documented, and validated. When feature definitions drift between teams, model outputs become untrustworthy even if the code still runs.
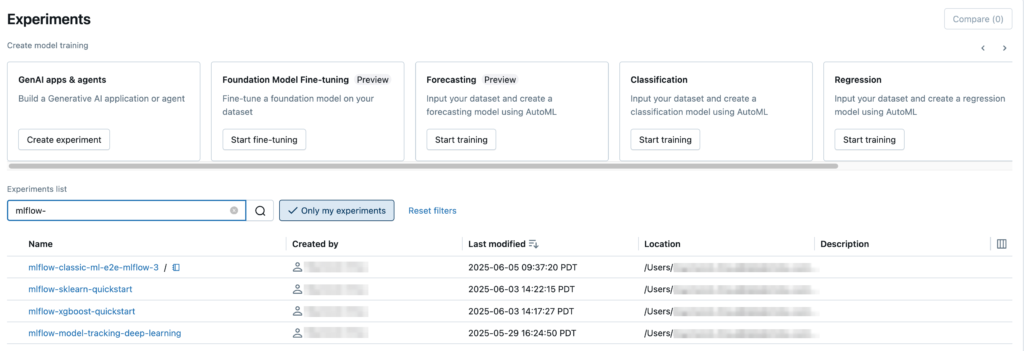
3) Make MLOps a discipline, not a hero story
Source: https://docs.databricks.com/aws/en/mlflow/experiments
For real impact, you need repeatable training, clear promotion gates, and a deployment pattern that is designed for reliability. On Databricks, I typically see strong results when teams standardize on MLflow for tracking, registered model governance, and a clear separation between development and production workloads. When you do this well, model releases become routine, not risky.
To operationalize inference, teams often use Mosaic AI Model Serving so models are deployed as managed endpoints that support real time and batch inference. If you want to explore the official feature set, you can start with this Databricks resource.
Real time inference: better decisions during the race
During a race, AI value is not only accuracy, it is timing. Real time inference turns live telemetry into recommendations while there is still time to act. This helps teams optimize strategy timing such as pit windows and undercut or overcut probability, manage risk by detecting emerging thermal or component issues early, and support driver guidance with concise signals on where pace is being lost.
Just as important is interaction in the moment. When engineers can interrogate the freshest governed data and validate recommendations quickly, the decision loop tightens dramatically. This is where Databricks Genie adds a practical edge: it enables natural language exploration of trusted telemetry tables, helping teams understand the “why” behind a recommendation in seconds while preserving governance and transparency.
To keep real time AI reliable, align on three essentials: fresh inputs from low latency pipelines, clear serving SLAs with sensible fallback behavior, and monitoring on data health plus prediction stability.
Where Databricks Genie changes the conversation
One of the most practical shifts I have seen recently is the rise of governed, natural language analytics. This is exactly where Databricks Genie becomes a force multiplier.
In a high pressure environment, the strategy lead does not want a lecture on SQL. They want a confident answer to questions like: what happened to degradation when track temperature climbed, or how pit windows shifted under traffic. Genie makes that conversation possible because it lets business users ask questions in natural language against governed datasets, and it can show the generated query and results for transparency.
The important part is not the chat experience. The important part is trust. When Genie is configured on top of governed assets, it becomes a bridge between technical depth and operational speed. I often recommend starting with a focused, high value Genie space for race operations and performance engineering, then expanding as users learn what good questions look like.
For the official Databricks overview, see here. If you want practical adoption tactics we use in the field, I published Databricks Genie best practices on our blog.
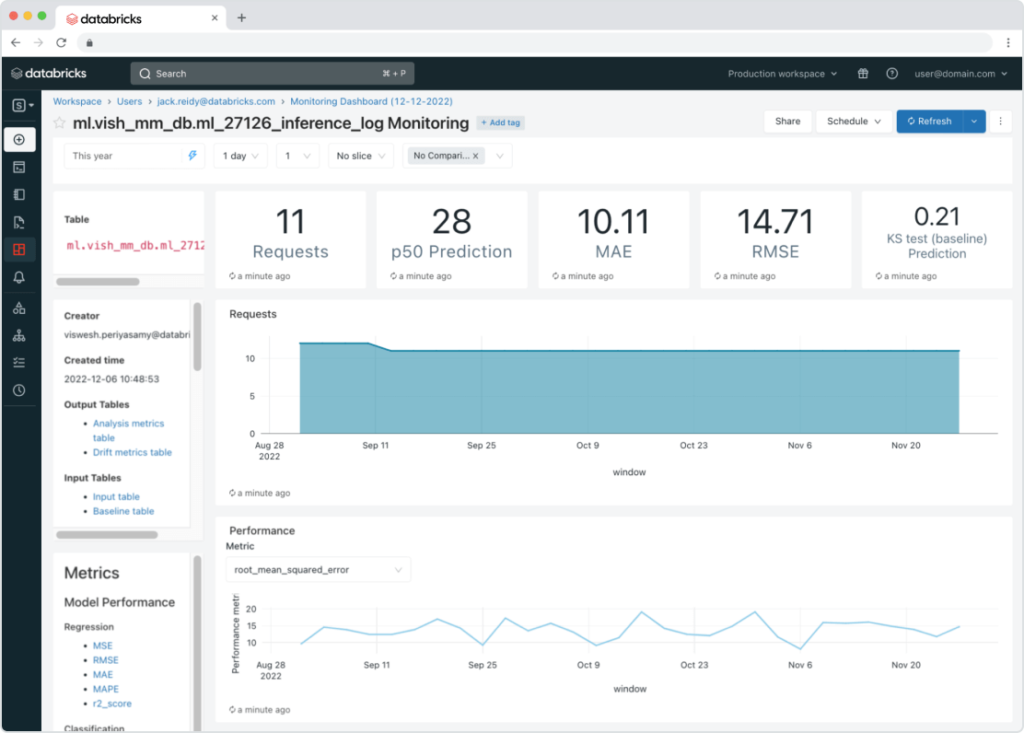
Monitoring, guardrails, and responsible AI in production
Production AI fails quietly unless you design for observability. You need monitoring that covers both data health and model behavior, including drift, anomalies, and inference quality.
Databricks Lakehouse Monitoring is designed to monitor data and AI assets in a unified way, including model inputs and predictions when they are logged to inference tables. You can read more here.
For teams building advanced AI systems, especially where GenAI is involved in decision workflows, I also recommend explicit guardrails and a clear governance posture. I recently shared our approach in Guardrails in AI Production.
A practical starting point
If you are building telemetry driven performance optimization, start small but build correctly.
- Unify data foundations with clear ownership, governance, and reliable tables.
- Standardize feature pipelines, quality checks, and ML lifecycle practices.
- Deploy with a serving pattern that supports monitoring and safe iteration.
If you want a structured implementation path, you can explore Entrada’s Race to the Lakehouse approach, which is designed to accelerate time to value while keeping architecture and governance standards high.
The promise is simple: when telemetry, governance, and AI delivery live in one system, you move from insights to action faster, and you keep that advantage weekend after weekend.