Data Engineering
Data Engineering  Data Strategy + Governance
Data Strategy + Governance  Data Migrations
Data Migrations  Concierge + Support
Concierge + Support  Artificial Intelligence
Artificial Intelligence  Training + Enablement
Training + Enablement  Data Analytics + Insights
Data Analytics + Insights  Financial Services
Financial Services  Communications, Media + Entertainment
Communications, Media + Entertainment  Healthcare + Life Sciences
Healthcare + Life Sciences  Technology + Digital Natives
Technology + Digital Natives  Manufacturing + Automotive
Manufacturing + Automotive  Public Sector
Public Sector  Retail + Consumer Goods
Retail + Consumer Goods  Race to the Lakehouse
Race to the Lakehouse  AI + Data Maturity Assessment
AI + Data Maturity Assessment  Unity Catalog
Unity Catalog  Rapid GenAI
Rapid GenAI  Modern Data Connectivity
Modern Data Connectivity  Gatehouse Security
Gatehouse Security  Health Check
Health Check  Sample Use Case Library
Sample Use Case Library  Blog
Blog  Events
Events  About Us
About Us  Careers
Careers  Founding Team
Founding Team 
As the Head of the AI Practice at Entrada, my daily focus is helping organizations deploy these solutions effectively. I have found that true reliability requires more than carefully crafted prompts.It demands building a Compound AI System supported by robust governance and architectural guardrails in AI production the Databricks Data Intelligence Platform.
Redefining Reliability in the Enterprise
Moving Beyond “Hallucination”
In enterprise discussions, “hallucination” is often used loosely as a buzzword, when in practice it requires a clear definition and captures more than just inaccurate responses. When I speak with clients, we work to technically define what reliability and trust actually mean. We have to ask: Is it just about accuracy, or does it include consistency and safety?
I believe reliability and trustworthiness extend far beyond simply providing accurate responses. This is why we are seeing the rise of “thinking models” that provide citations and traceability. We fundamentally need to understand not just the answer, but how and why the model came to that conclusion.
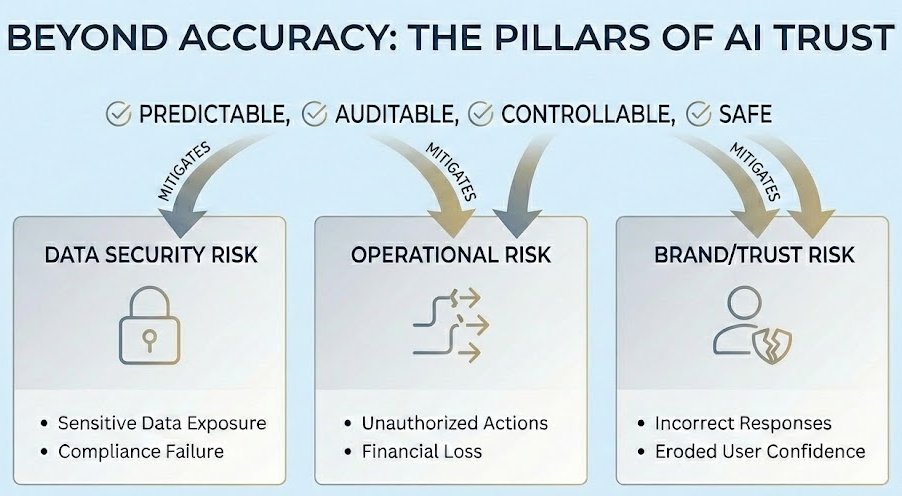
Accuracy alone is no longer deemed sufficient. Enterprises trust systems that are predictable, auditable, controllable, and safe.
When a client deploys a model without proper guardrails, the risk extends far beyond just incorrect answers. In my experience, the biggest risks include:
- Data Security Risk: Exposing sensitive data, whether through malicious exploitation or inadvertent access by the wrong user, undermines compliance obligations and damages trust in ways that are difficult and costly to reverse.
- Operational Risk: Non-deterministic behavior in customer-facing workflows can lead systems to take actions they shouldn’t (e.g. issuing refunds or making commitments without authorization). This quickly turns efficiency gains into financial loss and operational drag.
- Brand/Trust Risk: Confidently providing incorrect or inappropriate responses erodes user trust faster than latency issues. A loss of internal confidence in the tool can halt AI adoption altogether.
The Shift to Compound AI Systems
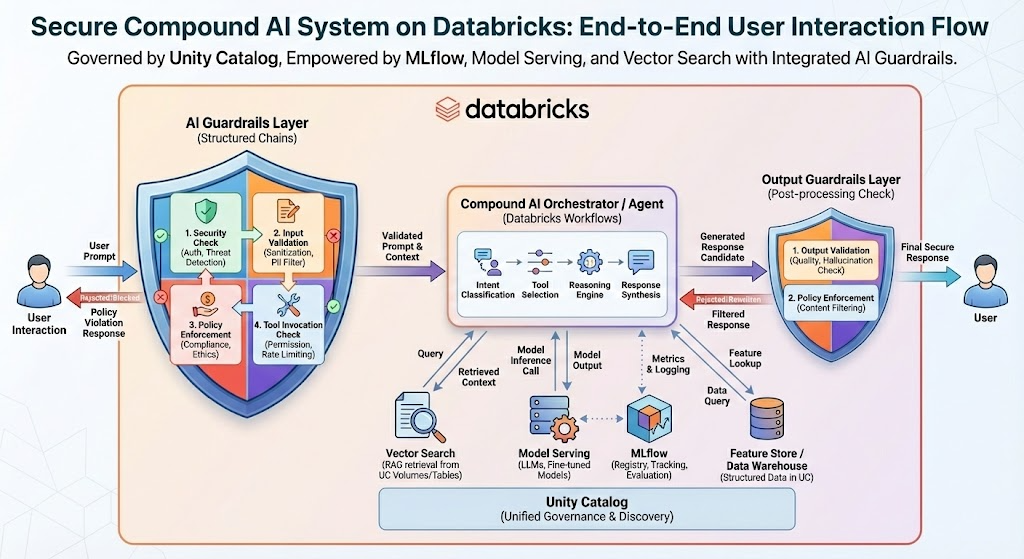
At Entrada, we align with Databricks’ vision of Compound AI Systems rather than relying on monolithic models. This choice is driven by the same enterprise risks outlined above. Security, operational reliability, and trust all break down when intelligence is treated as a single opaque capability.
I advocate for this modular approach because it breaks intelligence into specialized, inspectable components such as retrieval systems, classifiers, rule-based checks, and various models optimized for different roles. This architecture helps prevent errors by isolating failure to a single component, preventing the corruption of the whole system. Just as importantly, each component can be validated, monitored, and improved independently, enabling tighter controls and faster iteration without destabilizing production workflows.
The Databricks Advantage: Governance as a Guardrail
This modular architecture only works if reliability is enforced at every boundary between components. We utilize the Databricks platform to address reliability at every stage of the data life cycle. Unity Catalog acts as the “circuit breaker” of governance, providing centralized policies, scoped access, and auditability to prevent low-quality data from slipping through the cracks.
Security First with Unity Catalog
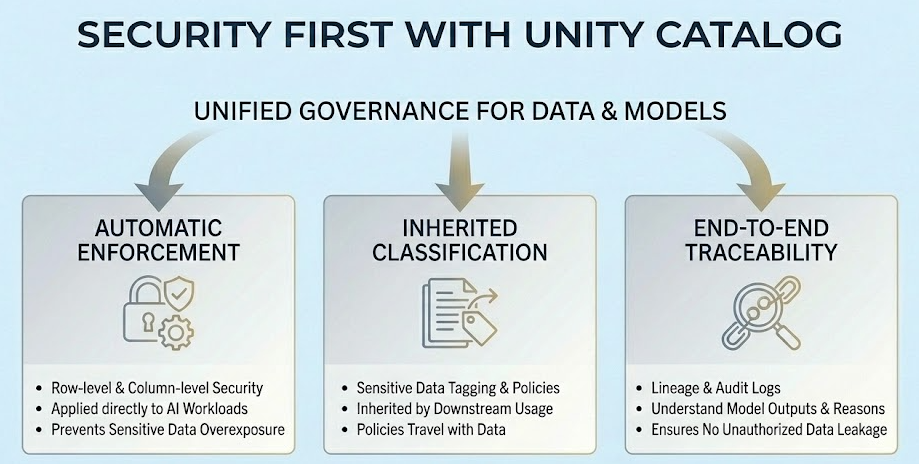
For enterprises, AI risk is fundamentally a data access problem; models simply surface the consequences. Unity Catalog acts as the backbone for our guardrails by providing unified governance across both data and models, inheriting fine-grained access controls from underlying tables and views.
In practice, this means governance is enforced automatically and consistently across AI workloads:
- Row-level and column-level security is applied directly to AI workloads, preventing overexposure of sensitive fields.
- Sensitive data classification and tagging are inherited by downstream usage, ensuring policies travel with the data.
- Lineage and audit logs provide end-to-end traceability, making it possible to understand not just what a model returned, but why.
By isolating information based on inherited user access, Databricks ensures AI systems cannot leak data users were never authorized to see in the first place.
Grounding Models with Vector Search
Retrieval Augmented Generation (RAG) systems are only as reliable as their retrieval layer. We use Databricks Vector Search to ground responses in high-quality enterprise data, ensuring retrieval is both scoped and repeatable. Support for hybrid search (vector + keyword) allows semantic relevance to be combined with exact term matching, while deterministic retrieval enables consistent responses across runs.
However, strong retrieval infrastructure does not eliminate the fundamentals. The “Garbage In, Garbage Out” problem still applies. The quality of grounded responses ultimately depends on the embedding strategy used to construct the vector index. Careful selection of embedding models, chunking strategies, and source data remains essential to achieving reliable outcomes.
Architectural Patterns for Enforcing Groundedness
While guardrails can be largely automated, I believe high-stakes use cases in financial, healthcare, and legal sectors still require a human-in-the-loop approach for final approval or exception handling. The goal is not to remove human review, but to implement progressive automation.
The Lifecycle of Guardrails in AI Production
My team’s approach to prompt engineering has evolved significantly. Early AI systems relied on single, complex prompts to manage everything from routing to policy enforcement. While effective in the short term, these prompts were hard to debug and prone to unintended failures.
Today, our prompts are lean and direct, aimed purely at producing language rather than managing multiple tasks.
To maintain stability and clarity, the surrounding logic should be handled outside of the prompt.
Structured functions or guardrail chains should control the logic for input validation, tool invocation, and policy enforcement. Isolating such logic into structured functions rather than keeping them in the prompt improves stability, reusability, and explainability. Prompting should be reserved for the interface rather than serving as logic containers for business logic or policy rules.
Automated Evaluation with MLflow
We operationalize Mosaic AI Model Serving and MLflow Evaluation, creating pre-production gates that provide continuous monitoring to prevent off-topic answers or unsafe responses from reaching users. Model Serving provides secure, scalable, and observable endpoints and enables request/response logging for auditing and debugging, while MLflow allows for programmatic evaluation of outputs using metrics for accuracy, relevance, groundedness, and safety compliance. Together, these tools enable continuous monitoring and automated checks, ensuring that only high-quality, predictable responses are deployed.
Real World Lessons from the Frontlines
Deploying is just the first step; guardrails require maintenance to ensure reliability over time. I categorize model drift into three areas:
- Response quality drift: Answers slowly become less relevant, less grounded, or more verbose.
- Behavior drift: Models respond in ways that technically pass checks but deviate from intended behavior.
- Safety drift: Edge cases increase as usage expands in ways that were not architected for nor anticipated.
We address these risks using MLflow by comparing current outputs to previous baselines or periodically re-scoring live traffic against golden datasets. By turning drift into measurable metrics, we transform trust from a subjective feeling into a quantifiable signal.
Balancing Latency and Safety
A hidden complexity clients often overlook is managing the trade-off between latency and rigorous safety checks. Every additional safety check adds latency, and overly synchronous pipelines can damage the user experience.
Tiered checks let you catch errors efficiently without slowing the system. Fast, lightweight checks can be run inline, but deeper evaluations should be run asynchronously or post-response unless absolutely necessary.
Advice for Engineering Leaders
For teams looking to move from a proof of concept (POC) to a full production rollout, the most critical lesson is simple: do not scale POC architecture as-is.
POCs are typically optimized for speed and flexibility, focusing on experimentation and rapid iteration. In contrast, production environments must be optimized for control, observability, and governance.
During the POC phase, essential guardrails, such as Role Based Access Control (RBAC) and structured monitoring, are often missing. Scaling a POC out without implementing these safeguards can lead to serious security, operational, and compliance risks.
Building Trustworthy AI at Scale
Enterprise AI success is not defined by how smart a model is, but by how well the system is controlled. Failures happen when systems lack structure, visibility, and accountability.
Databricks’ approach, grounded in governance, modularity, and observability, allows our customers to confidently rely on AI-generated responses.
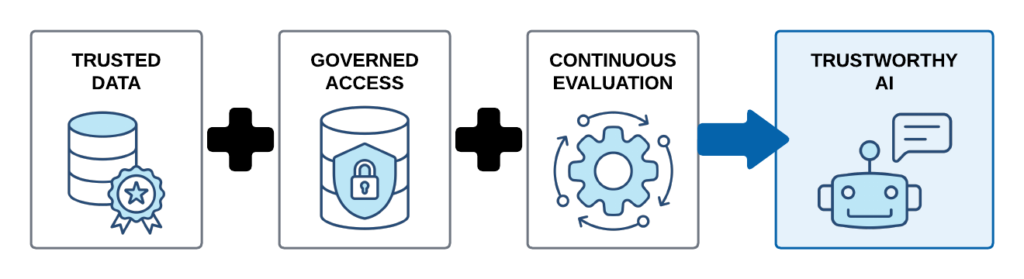
Trusted Data + Governed Access + Continuous Evaluation = Trustworthy AI.
Don’t ask “Can AI do this?” Ask “Can we rely on AI when it matters?”
Contact Entrada for an assessment of your current AI architecture or to learn more about safe production deployment.