 Data Engineering
Data Engineering  Data Strategy + Governance
Data Strategy + Governance  Data Migrations
Data Migrations  Concierge + Support
Concierge + Support  Artificial Intelligence
Artificial Intelligence  Training + Enablement
Training + Enablement  Data Analytics + Insights
Data Analytics + Insights  Financial Services
Financial Services  Communications, Media + Entertainment
Communications, Media + Entertainment  Healthcare + Life Sciences
Healthcare + Life Sciences  Technology + Digital Natives
Technology + Digital Natives  Manufacturing + Automotive
Manufacturing + Automotive  Public Sector
Public Sector  Retail + Consumer Goods
Retail + Consumer Goods  Race to the Lakehouse
Race to the Lakehouse  AI + Data Maturity Assessment
AI + Data Maturity Assessment  Unity Catalog
Unity Catalog  Rapid GenAI
Rapid GenAI  Modern Data Connectivity
Modern Data Connectivity  Gatehouse Security
Gatehouse Security  Health Check
Health Check  Sample Use Case Library
Sample Use Case Library  Blog
Blog  Events
Events  About Us
About Us  Careers
Careers  Founding Team
Founding Team 
The problem starts before the pipeline
Inside most mortgage technology stacks, there is an expensive silence. The CRM knows who raised a hand, the LOS knows who applied, and the servicing platform knows who already belongs to you – but none of them know who is about to transact. The market does not wait for a neat internal workflow. Borrowers list homes, pull permits, build equity, pick up second properties, refinance with competitors, and drift in and out of economic incentive long before any of those signals become a lead record.
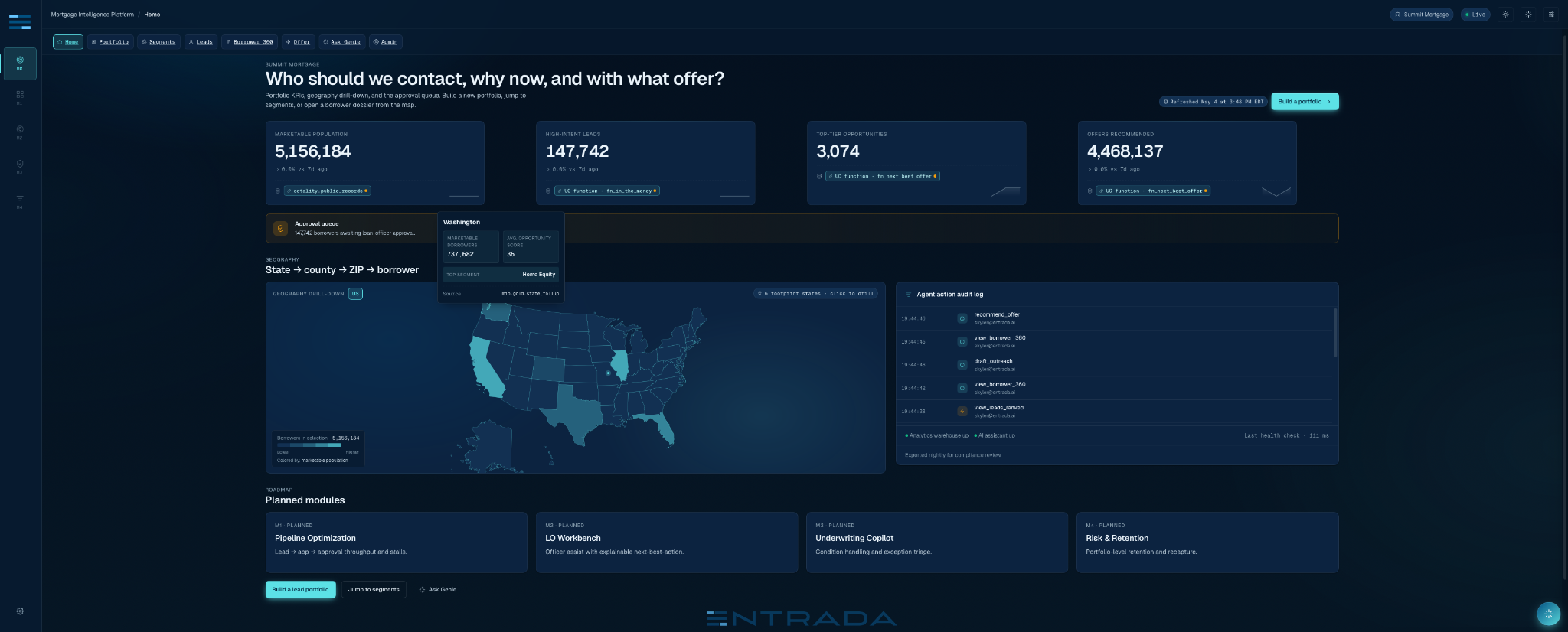
That is where Entrada’s Mortgage Intelligence Platform begins. Module 0, the part we are bringing to Databricks Data + AI Summit 2026 (and the initial offering of the app – we have four more planned), asks the question every growth team secretly wants answered before any funnel optimization matters: who should we contact, why now, and with what offer?
The answer is not “run a model over a spreadsheet”. It is a governed application architecture: Cotality property intelligence arriving through Databricks, a Unity Catalog contract that keeps the data story honest, a Databricks App that turns that story into a working product, Genie for governed natural language analysis, and Lakebase for the state that analytics tables should never pretend to be.
| THE THESIS The technical lesson is simple but easy to miss – a useful AI app needs three separate things that must not be collapsed into one table: analytical truth, semantic meaning, and operational memory. |
A trillion dollar market with a lead quality problem
Mortgage lending has never been short on data. It has been short on timely, explainable, action ready data. In a market where the Mortgage Bankers Association forecast total single family origination volume to rise to $2.2 trillion in 2026, the fight is not just for application throughput. It is for borrower attention before a competitor gets there first.
Most lenders already have mature systems for the middle and end of the funnel. That is exactly why Module 0 lives at the top. It does not replace the LOS, CRM, servicing system, or marketing automation platform. It feeds them a better starting population: borrowers who have a reason to transact now, a product that plausibly fits, and a trail of evidence a compliance reviewer can reconstruct later.
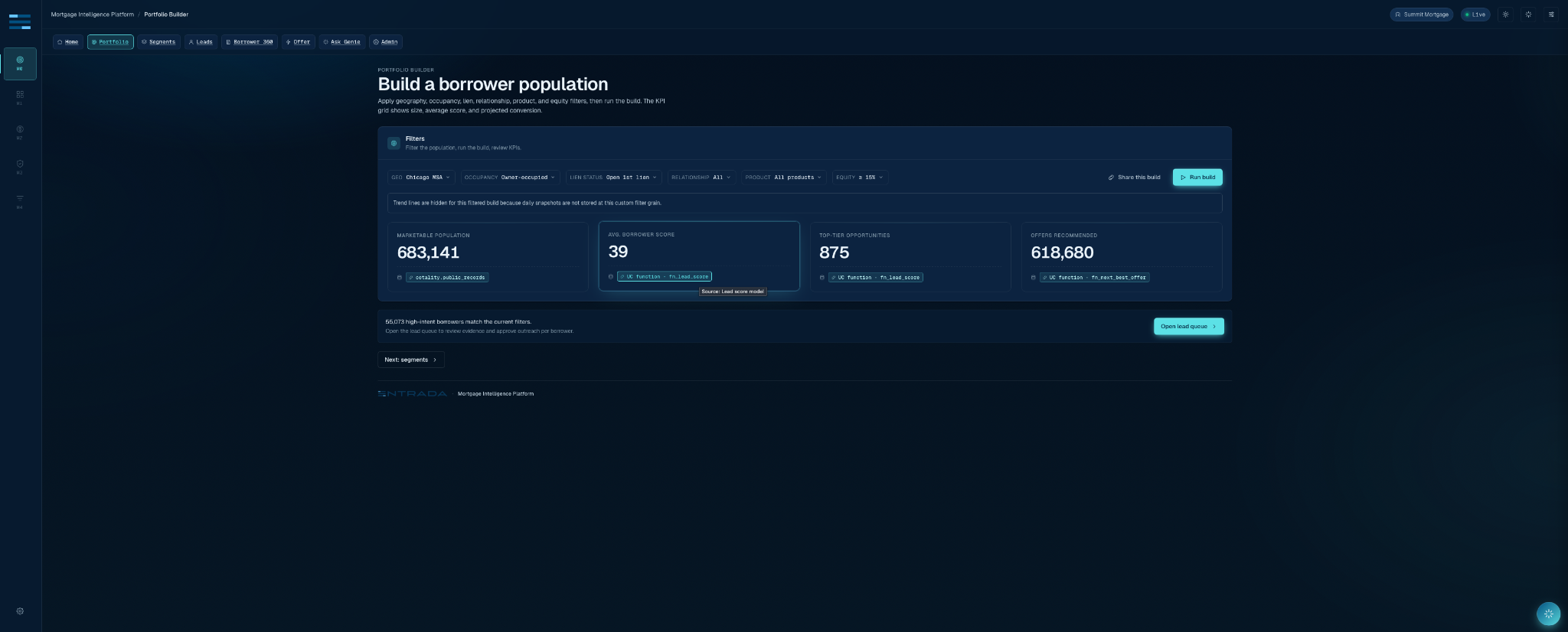
The core user journey is deliberately plain. A growth lead selects geography, occupancy, open lien status, lender relationship, target product, and policy thresholds. The app returns a marketable population, segment membership, a lead queue, a borrower dossier, a next-best-offer recommendation, and an approval record. The magic is not hidden in the UI. The UI is where the contract is forced to tell the truth.
Cotality provides the property truth; Databricks makes it operable
The data foundation is a partnership pattern. Cotality brings property intelligence: CLIP for property identity, Owner Link for ownership relationships, public-record and lien signals, valuation context, listing and permit triggers, and property level drill-down through CLIP-MCP. Databricks gives that data a governed execution home: Delta Sharing into Unity Catalog, SQL Warehouse for app queries, metric views for trusted definitions, Genie for governed questions, and Apps for the product surface.
That last sentence is especially important. In mortgage, “data access” is not the same as “usable data.” A lender can license a magnificent dataset and still leave loan officers guessing. Module 0 does the unglamorous translation work: property events become borrower evidence; borrower evidence becomes segment membership; segment membership becomes product-aware recommendation; recommendation becomes an approval record.
The point of CLIP and Owner Link inside this app is not to decorate a dashboard. It is to make “why this borrower?” a reproducible join path instead of tribal knowledge.
The data contract: raw is not a product
Experienced Databricks engineers will recognize the pattern: the implementation succeeds or fails at the boundary between silver and gold. Module 0 treats the gold layer as an API, not as a convenience schema. The app does not browse raw Cotality shares. It does not let Genie wander through intermediate feature tables. It reads curated borrower, lead, segment, score, evidence, and semantic surfaces.
That posture prevented two common failures. First, it kept raw names, addresses, and mastered identifiers out of the browser. Second, it made the product explainable. Every score can point to the components that created it. Every segment can point to the predicate that admitted the borrower. Every recommendation can point back to source evidence rather than a black-box “AI said so” label.
Scoring belongs in governed functions, not slideware
Module 0 uses deterministic scoring primitives where the business rules should be deterministic: rate spread, in-the-money eligibility, lead score, and next-best-offer. The implementation uses Unity Catalog SQL functions for the canonical path and Python parity fixtures for testability. That is not overengineering. It is how a product team keeps a demo, an API, a dashboard, and Genie from quietly disagreeing.
Implementation pattern: keep the score as a governed SQL primitive and pin parity in tests.
-- abbreviated from mip.gold.fn_lead_score
RETURN LEAST(100, GREATEST(0, CAST(BROUND(
0.35 * COALESCE(economic_incentive, 0)
+ 0.30 * COALESCE(intent_trigger, 0)
+ 0.15 * COALESCE(fit, 0)
+ 0.10 * COALESCE(relationship, 0)
+ 0.10 * COALESCE(evidence, 0)
) AS INT)));The lead score is intentionally boring. It should be. Sophisticated teams sometimes mistake novelty for maturity. In a regulated workflow, a simple rule with frozen semantics, tests, and source evidence beats a mysterious model that cannot survive the first compliance question. MLflow and Agent Bricks are natural extensions for later modules, but Module 0 starts by making the deterministic path trustworthy.
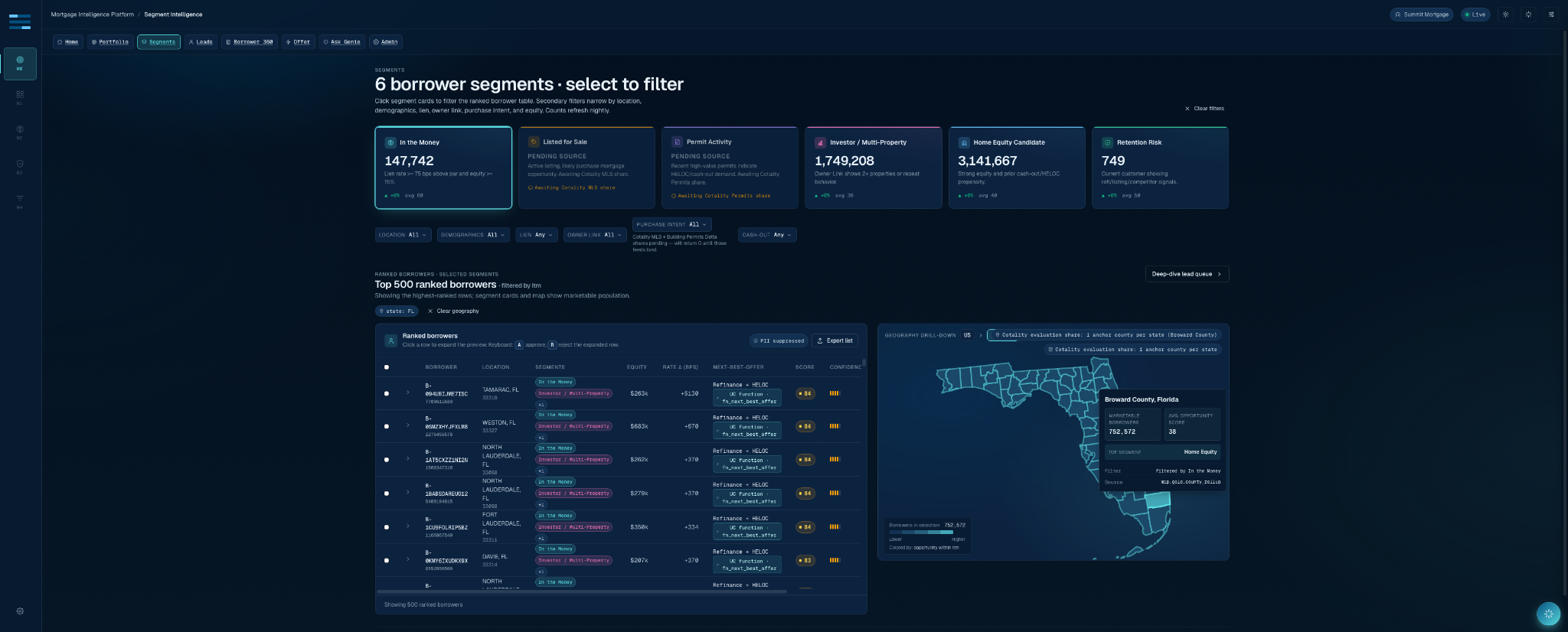
The next-best-offer primitive follows the same philosophy. A listed property leads to purchase mortgage. A borrower with rate spread and enough equity can earn a refi-plus-HELOC recommendation. A permit plus equity can route to HELOC. Investor and retention logic follow their own branches. The app can explain why a runner-up offer lost, which is the kind of detail business users notice immediately.
Genie works best when it has a fence
The Genie integration is a good example of a technical choice that looks small and changes everything. We did not wire Genie to the whole workspace. The Mortgage Lead Intelligence Genie Space is grounded in a narrow list of trusted assets: gold lead population, segment population, lead scores, borrower 360, evidence events, and metric views for lead generation, segment performance, and borrower opportunity.
That is the difference between “natural-language access to data” and “a governed analytical interface.” The space is taught the business terms that matter: in-the-money borrowers, HELOC candidates, segment performance, source evidence, opportunity score, approval rate. It is also taught what not to do: do not enumerate random schemas, do not extract raw PII, do not answer protected-class targeting requests, and do not pretend to know data that is not in the trusted asset list.
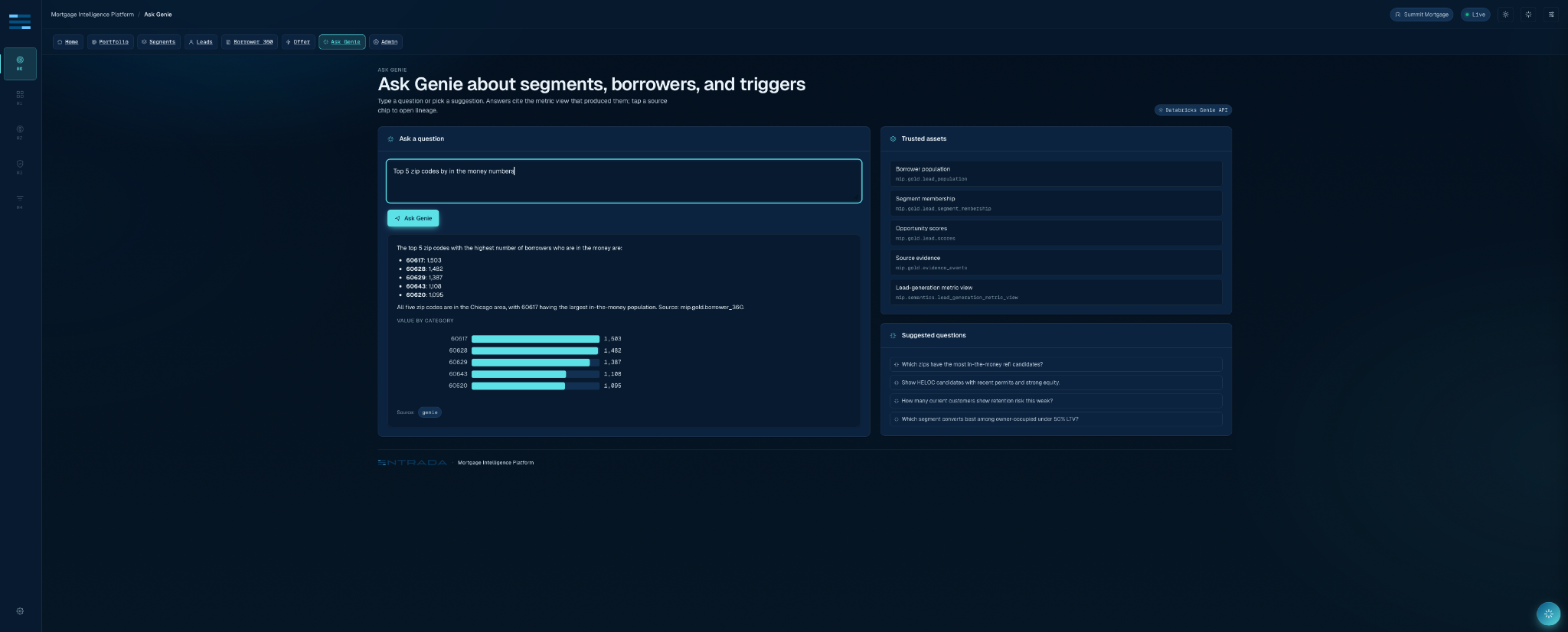
The takeaway for Databricks teams is practical: Genie quality is not mainly a prompt writing contest. It is a semantic supply chain problem. The better the tables, metrics, examples, and refusal rules, the less the assistant has to improvise. Module 0’s Genie experience works because it inherits a disciplined data contract rather than trying to patch one in the chat box.
Lakebase is where the app becomes accountable
Analytical tables are excellent at facts about the world. They are a bad place to fake user decisions. Module 0 uses Lakebase Postgres for the operational memory of the application: campaign definitions, approval decisions, action audit, agent sessions, and feedback. This is where a recommendation becomes something a human reviewed. It is also where the system records enough context for a later compliance conversation.
Implementation pattern: Lakebase stores decisions with idempotency, not just screenshots of decisions.
CREATE TABLE IF NOT EXISTS mip_app.approvals (
approval_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
campaign_id UUID REFERENCES mip_app.campaigns(campaign_id),
borrower_id TEXT NOT NULL,
offer_code TEXT,
action TEXT NOT NULL CHECK (action IN ('approve','reject','hold')),
actor_email TEXT NOT NULL,
rationale TEXT,
request_id TEXT,
decided_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
CREATE UNIQUE INDEX IF NOT EXISTS idx_approvals_request_id
ON mip_app.approvals (request_id) WHERE request_id IS NOT NULL;This split is one of the most important architectural choices in the product. Unity Catalog governs the analytical truth. Lakebase records operational state. Genie reads the former. The FastAPI service writes the latter. The browser never needs raw source data to give the user a confident answer.
Databricks Apps made the product boundary smaller
The app itself is a React and TypeScript frontend served by a FastAPI backend, deployed as a Databricks App. The app binds to platform resources rather than smuggling credentials through a sidecar: SQL Warehouse for gold-table queries, Genie for conversational analytics, and Lakebase for app state. The runtime reads Databricks resource bindings and fails visibly when a dependency is missing.
Implementation pattern: the app declares the Databricks resources it needs instead of carrying its own infrastructure story.
resources:
- name: sql_warehouse
sql_warehouse:
permission: CAN_USE
- name: genie_space
genie_space:
permission: CAN_RUN
- name: database
database:
permission: CAN_CONNECT_AND_CREATEThis is also where the “no silent mock fallback” rule pays off. Demo apps often die by pretending. The first failure looks harmless. a fake number here, a fallback response there, and then nobody knows which surface is real. Module 0 takes the opposite posture: dependency failures surface as degraded states; audit writes use idempotency; SQL statements are parameterized; logs carry statement hashes and correlation IDs rather than leaking PII adjacent values.
For a Databricks engineer, that is the deeper product lesson. The hard part is not getting a React app to call a warehouse. The hard part is making every boundary honest enough that the field team can demo it, the customer team can extend it, and the governance team can ask hostile questions without collapsing the architecture.
The user story is intentionally short
A mortgage growth leader opens the app and starts with the portfolio. They choose a footprint and product strategy. The Segment Intelligence page shows six borrower segments: in the money, listed for sale, permit activity, investor or multi-property, home equity candidate, and retention risk. The lead queue ranks borrowers by opportunity score and “why now” evidence. Borrower 360 provides the property and ownership context. The Offer Orchestrator recommends a product and drafts an outreach message for review only. A human approves or rejects. Lakebase records the decision.
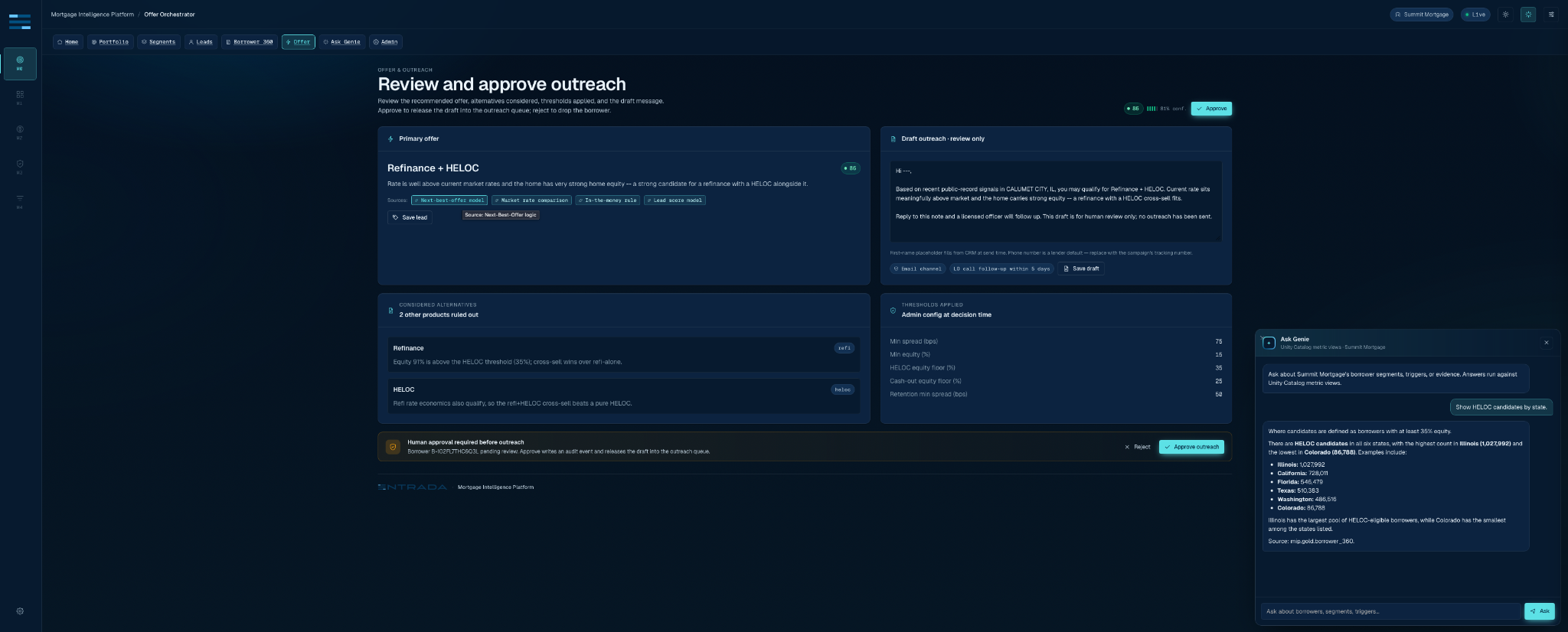
The workflow is short because the app has already done the long work upstream. It has normalized source signals, filtered the population, pinned the scoring semantics, constrained Genie, and separated action state from analytical state. To the user, it feels like a clean product. To a data engineer, it should look like a lot of careful seams.
What experienced Databricks engineers should steal from this build
Treat gold tables like product APIs. If a frontend, dashboard, API, and Genie space all depend on the same concept, the concept deserves a stable gold or semantic surface. “It works in a notebook” is not a contract.
Keep operational state out of analytical fiction. Approvals, request IDs, feedback, and agent sessions belong in an OLTP store. Lakebase gives Databricks apps a clean place to record what people did.
Make source evidence a first class table. A score without evidence is an argument. Evidence events turn borrower targeting into a reconstructable chain of signals.
Constrain conversational analytics before users ask the first question. Genie is strongest when the space has curated assets, examples, definitions, and refusal rules. The best guardrail is a good semantic layer.
Fail visibly. An app that admits “that question can’t be answered with the available data” is safer than an app that returns fake numbers with confidence. This matters even more in regulated workflows.
Where Module 0 goes next
Module 0 is the lead generation layer. The same architecture is designed to support the rest of the Mortgage Intelligence Platform: Pipeline Optimization, the Loan Officer Workbench, an Underwriting Copilot, and Risk & Retention. Those modules will bring more LOS, CRM, servicing, underwriting, and portfolio risk data into the picture. But the pattern stays the same: Cotality property intelligence, Databricks governance and AI, Entrada workflow implementation, and human accountability at the point of action.
Agent Bricks is the natural next step for multi-step workflows that need to coordinate a Genie Space, Unity Catalog functions, CLIP-MCP property tools, custom agents, and approval logic. The important thing is that Module 0 already laid the rails: trusted data, tested scoring, auditable state, and a user experience that makes the “why” as visible as the “what.”
Come see it at DAIS 2026
We will be demoing the Entrada Mortgage Intelligence Platform at our booth during Databricks Data + AI Summit. Stop by and ask us to show the whole Module 0 path: build a portfolio, filter segments, open a ranked borrower, inspect the evidence, ask Genie a governed question, approve an offer, and then find the audit record. That last step is the one we like showing most, because it proves the product is not just a beautiful screen. It is a governed system of record for mortgage intelligence decisions.
The mortgage market does not need another dashboard that explains yesterday. It needs a signal layer that tells teams what to do next, why they can trust it, and how to prove what happened afterward. That is the product we built.
Technical references


