Data Engineering
Data Engineering  Data Strategy + Governance
Data Strategy + Governance  Data Migrations
Data Migrations  Concierge + Support
Concierge + Support  Artificial Intelligence
Artificial Intelligence  Training + Enablement
Training + Enablement  Data Analytics + Insights
Data Analytics + Insights  Financial Services
Financial Services  Communications, Media + Entertainment
Communications, Media + Entertainment  Healthcare + Life Sciences
Healthcare + Life Sciences  Technology + Digital Natives
Technology + Digital Natives  Manufacturing + Automotive
Manufacturing + Automotive  Public Sector
Public Sector  Retail + Consumer Goods
Retail + Consumer Goods  Race to the Lakehouse
Race to the Lakehouse  AI + Data Maturity Assessment
AI + Data Maturity Assessment  Unity Catalog
Unity Catalog  Rapid GenAI
Rapid GenAI  Modern Data Connectivity
Modern Data Connectivity  Gatehouse Security
Gatehouse Security  Health Check
Health Check  Sample Use Case Library
Sample Use Case Library  Blog
Blog  Events
Events  About Us
About Us  Careers
Careers  Founding Team
Founding Team 
Over the last several years of building AI systems and Databricks implementations for Entrada, I have learned that the best path to the uncomfortable truth is:
The model is rarely the bottleneck.
Your data is.
Foundation models will increasingly become a commodity. It’s the data that you own, the quality of which is the only competitive advantage that really matters. And the fact is, for most organizations, the bottleneck is actually:
Is the data you have discoverable, credible, and well-governed enough for any model?
Many organizations are currently test driving Ferraris with garden hose fuel. In the environments I have examined, perhaps 10-15% of organizations have anything approaching the “high-performance fuel system” that GenAI, for real, needs.
The remaining nine operate with an AI team asking the data team, “Can you send me a fresh export?” every time they wish to retrain the model.
That’s not a pipeline.
That’s a bottleneck.
The “Garbage In, Hallucination Out” Reality Check
We all know the phrase Garbage In, Garbage Out. In the classic BI environment, it could refer to a weird chart, a poor KPI, or a dashboard that doesn’t smell right.
With GenAI, the failure mode is much more dangerous because:
Poor data → fluent, confident, and beautiful lies.
There is none that lights up red when the LLM hallucinates – and certainly not a universal, push-button one. Therefore, the defenses need to be architectural:
- Observability – be very specific about which chunks of the data were actually retrieved, from which documents, and when those documents were last updated. If you cannot display “what the model actually saw,” you’re flying blind.
- Citation Enforcement – it should require the model to give citations for sources, which can then be checked programmatically for existence and relevance.
- Semantic Drift Detection – keep track of when users ask questions that are not within the coverage of the knowledge base that you have.
This is where data engineering becomes existential for GenAI accuracy.
Architecture First: The Medallion Architecture for AI
When organizations purchase the latest model without data maturity, Day 1 will typically consist of “hero work” where a handful of folks are hacking together CSVs for a proof of concept. This will not scale.
To scale, you require architectural rigor.
Unstructured Data: The Challenge, and the Importance of Lakehouse
The traditional data warehouse was developed for structured analysis. GenAI needs:
- Structured data
- Semi-structured logs
- Unstructured data, images, and PDFs
- Vector embeddings
- Metadata and lineage
- Unified governance for all of the above
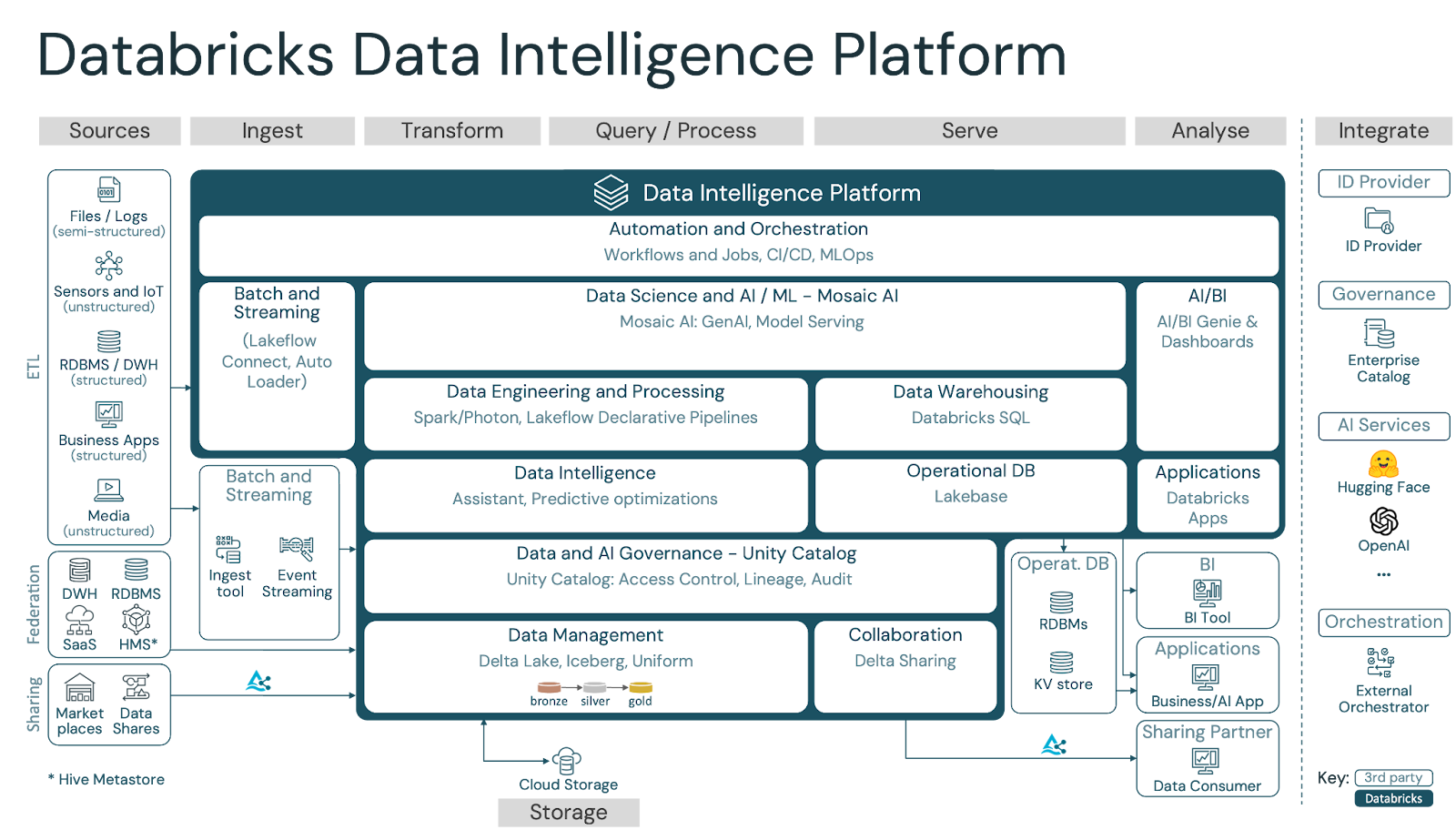
The Databricks Data Intelligence Platform, developed using the Lakehouse architecture, is among the soundest platforms for this because it offers:
- Only one storage layer (Delta Lake) for warehouse-grade reliability
- Single layer of governance (Unity Catalog) for data, models, features, and vector indexes
- Native vector search and AI tooling (Mosaic AI)
- The ability to work with both unstructured and structured data simultaneously without “ETL spaghetti”
It is this convergence of data, computation, embeddings, and governance that allows GenAI systems to run safely and at scale.
Applying Bronze, Silver, and Gold to RAG
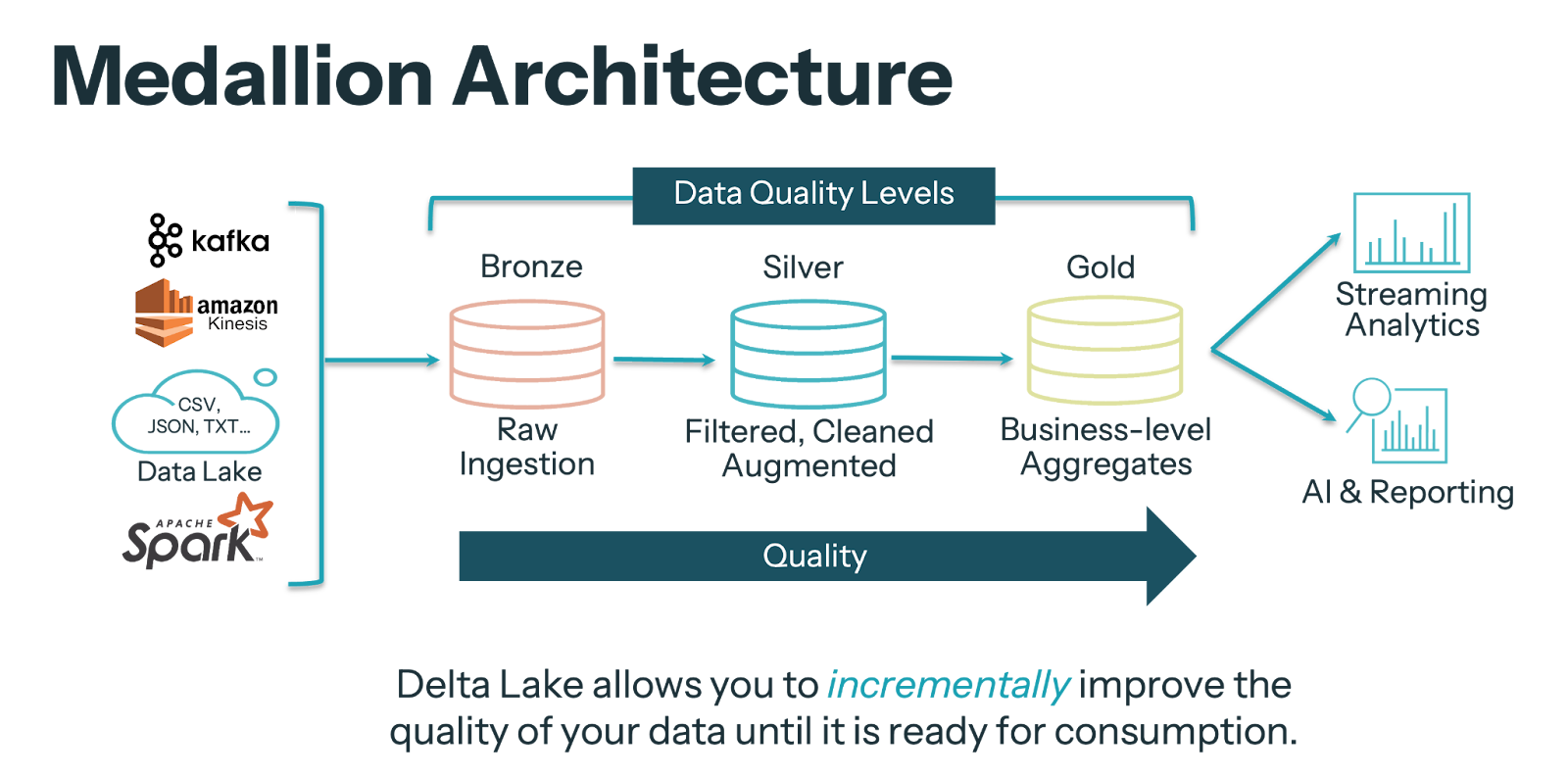
RAG is not a product, it’s a pipeline.
To figure out whether you actually have a pipeline or simply “random stuff in a bucket,” ask these three questions of your system:
- What document did this answer come from?
- When was the document last updated?
- Who is authorized to view it?
If the members of your team are not able to do these three within a minute, you are not ready for the production environment.
Here’s the mapping of the Medallion Architecture onto GenAI:
Bronze – Raw Documents
Land raw PDFs, Confluence pages, emails, and metadata about files into Delta tables or Volumes, unchanged. Do not alter provenance.
Silver – Refined, Chunked, Embedded
- Normalize the data, removing any duplicates
- Chunk text
- Create embeddings
- Store them in structured Delta tables along with semantic metadata
Gold – Curated and Governed Corpora
- Develop use case specific governed views (Customer Support KB, HR Policies, Engineering Handbook)
- Use Unity Catalog security on this, ensuring that your RAG data pipeline only extracts data that the users have access to
This provides you with lineage, observability, reproducibility, and enforceable access control.
Silent Killer: Governance and Security in the Age of AI
The number one GenAI fear among CISOs and business leaders is:
“Will the chatbot leak confidential data?”
But, unfortunately, what these systems do is actually create that very risk, specifically where the documents are stored in external vectors that do not relate to enterprise management.
The Significance of Unity Catalog for GenAI
The “circuit breaker” of governance for your AI environment is the Unity Catalog. It provides the following:
- Centralized Policies – Permissions are defined centrally, applicable for SQL, notebooks, dashboards, machine learning, and RAG retrieval.
- Scoped Access – AI systems access defined Gold tables/views, not unrestricted corpora.
- Auditability – Each access request, whether it’s data, embedding, or model call, is recorded for auditing purposes.
When used together with Mosaic AI Vector Search, the vector indexes reside within the Unity Catalog, inheriting the row/column security and data masking rules of the underlying data. This removes the loophole where the intern could accidentally query the very same semantic index that the CHRO uses.
This is the current definition for security-aware retrieval.
Accelerating Time-to-Value with the Data Intelligence Platform
Reducing the “Data Gravity Tax”
In organizations, the data warehouse, data lake, ML environment, and vector storage are often separated. This creates a measurable cost:
- Weeks of engineering time to sync data
- Constant breakage because of schema changes
- Duplicated permissions
- Drift between environments
Throughout my field experience, the average loss of velocity for the teams has been 30% to 50% because of this cross-system coordination.
With the Databricks Data Intelligence Platform:
- Data lives once
- Governance is unified
- Models and agents operate where the data already resides
- New Gold tables are immediately searchable and queryable on the basis of the same permissions and lineage
This speeds up the iterative process for AI development teams considerably.
Champion’s Audit: Evaluating the Maturity of GenAI
After conducting audits on numerous enterprise setups, I immediately identify the following three red flags:
- No Single Source of Truth – If the data resides in shadow systems numbering in the dozens with no enterprise catalog, you’re not ready.
- Ad-Hoc Pipelines that Run on Cron Jobs – This will ensure inconsistent model data and results.
- Governance Bolted On – If each tool is responsible for its own authorization, GenAI will become a problem.
The First Step Executives Should Take Today
It is premature to appoint AI scientists until you have developed your data foundation. They will use 60-80% of their time on incidental data engineering – cleaning CSVs, reverse-engineering schemas, wiring exports. That’s a $300K expert doing $80K work, and they will burn out.
The Executive Mandate
Before adding new personnel to the AI staff:
- Assign a leader for the implementation of a single Lakehouse platform and catalog.
- Perform the following test: Pick your top 3 use cases for AI. Ask your data people: “Can you give me a governed, documented, automatically refreshed data set for these, today?”
If the answer is no, then you know where the next investment should go.
Conclusion
Excellent AI demands excellent data engineering. The truth is that unless you have a firm foundation – designed with Medallion architecture, governed with Unity Catalog, and powered with Mosaic AI – your GenAI strategy will likely struggle past POC.
You do not need a better model.
You need better data.
And the maturity to deliver it – data engineering maturity.