 Data Engineering
Data Engineering  Data Strategy + Governance
Data Strategy + Governance  Data Migrations
Data Migrations  Concierge + Support
Concierge + Support  Artificial Intelligence
Artificial Intelligence  Training + Enablement
Training + Enablement  Data Analytics + Insights
Data Analytics + Insights  Financial Services
Financial Services  Communications, Media + Entertainment
Communications, Media + Entertainment  Healthcare + Life Sciences
Healthcare + Life Sciences  Technology + Digital Natives
Technology + Digital Natives  Manufacturing + Automotive
Manufacturing + Automotive  Public Sector
Public Sector  Retail + Consumer Goods
Retail + Consumer Goods  Race to the Lakehouse
Race to the Lakehouse  AI + Data Maturity Assessment
AI + Data Maturity Assessment  Unity Catalog
Unity Catalog  Rapid GenAI
Rapid GenAI  Modern Data Connectivity
Modern Data Connectivity  Gatehouse Security
Gatehouse Security  Health Check
Health Check  Sample Use Case Library
Sample Use Case Library  Blog
Blog  Events
Events  About Us
About Us  Careers
Careers  Founding Team
Founding Team 
This gap – between operational success and business confidence – is at the heart of why pipeline-centric thinking is breaking down beyond 2025.
I have seen this pattern repeatedly across large enterprises. In my experience, most organizations are not failing because they lack pipelines. They are failing because they mistake data movement for data value.
The next phase of data engineering is not about building faster or more resilient ETL. It is about engineering Data Products: trusted, discoverable, governed assets that are owned by domains, consumed by real users, and measured by impact – not uptime.
This shift is not theoretical. It is being actively enabled by the Databricks Data Intelligence Platform, which provides the governance, quality enforcement, discoverability, and intelligence required to treat data as a first-class product rather than a by-product of pipelines.
Redefining Success in Data Engineering
Why Pipeline Uptime Is the Wrong North Star
For more than a decade, data engineering maturity was measured by throughput and reliability: did the job run, and did it finish on time? Those metrics still matter – but they are no longer sufficient.
Pipeline uptime is an internal optimization metric, not a business outcome. A pipeline can be “green” and still produce data that is:
- Semantically misunderstood
- Stale relative to decision timelines
- Inconsistent across domains
- Quietly broken due to upstream changes
In contrast, a Data Product reframes success around:
- Usability: Can a consumer understand and safely use this data without tribal knowledge?
- Trust: Are freshness, quality, and definitions explicitly enforced?
- Reliability: Are contracts defined and monitored, not assumed?
- ROI: Does this asset drive decisions, automation, or revenue?
In this model, data engineering success looks much closer to how modern software teams think about APIs and services – clear contracts, observable behavior, and accountability.
What “Data Product” Actually Means
A Data Product is not simply a “gold table with better documentation.” A Data Product has several defining characteristics:
- Domain ownership: It is owned by the team closest to the business logic.
- Explicit contracts: Quality, freshness, and schema expectations are defined and enforced.
- Discoverability: Consumers can find, evaluate, and understand it without direct engineering support.
- Governance by design: Access, lineage, and compliance are intrinsic, not bolted on later.
This naturally aligns with data mesh principles – but with an important caveat. Without strong platform-level governance and enforcement, decentralization simply creates distributed chaos. The shift from pipelines to products only works if the platform enforces consistency and trust.
The Databricks Advantage: The Data Intelligence Platform
Unity Catalog as the Data Product Marketplace
In practice, most enterprises already have thousands of tables. What they lack is a way to distinguish products from raw assets.
Unity Catalog is the backbone that turns a lakehouse into a data product marketplace. Through centralized governance, Unity Catalog enables:
- Clear ownership: Every dataset is associated with accountable teams.
- End-to-end lineage: Consumers understand where data comes from and what depends on it.
- Rich metadata and tagging: Domains, sensitivity, freshness expectations, and semantics become queryable signals.
- Consistent access control: Security and compliance are enforced uniformly across workloads.
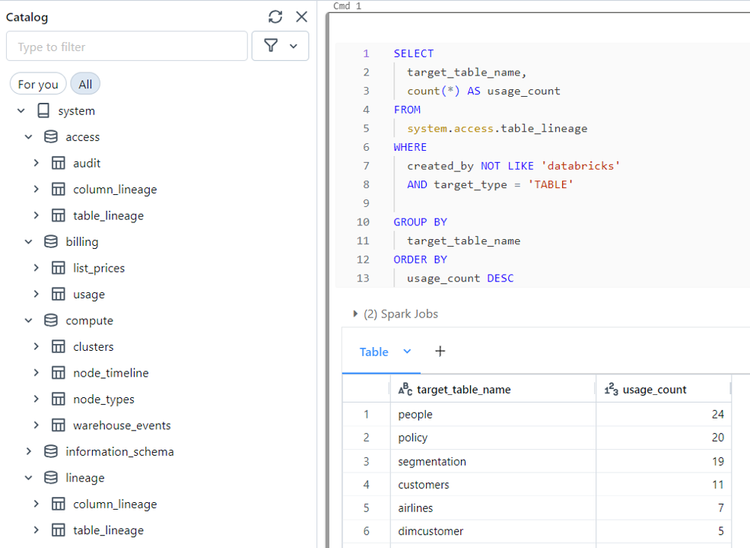
Query-level lineage and usage metrics make data products observable, measurable, and governable at scale.
When paired with Delta Sharing and the Databricks Marketplace, this model extends beyond internal analytics. Data Products can be safely shared across business units, partners, or even external consumers – without duplicating data or compromising governance.
The result is a fundamental shift: tables stop being passive artifacts and start behaving like shoppable products with context, contracts, and accountability.
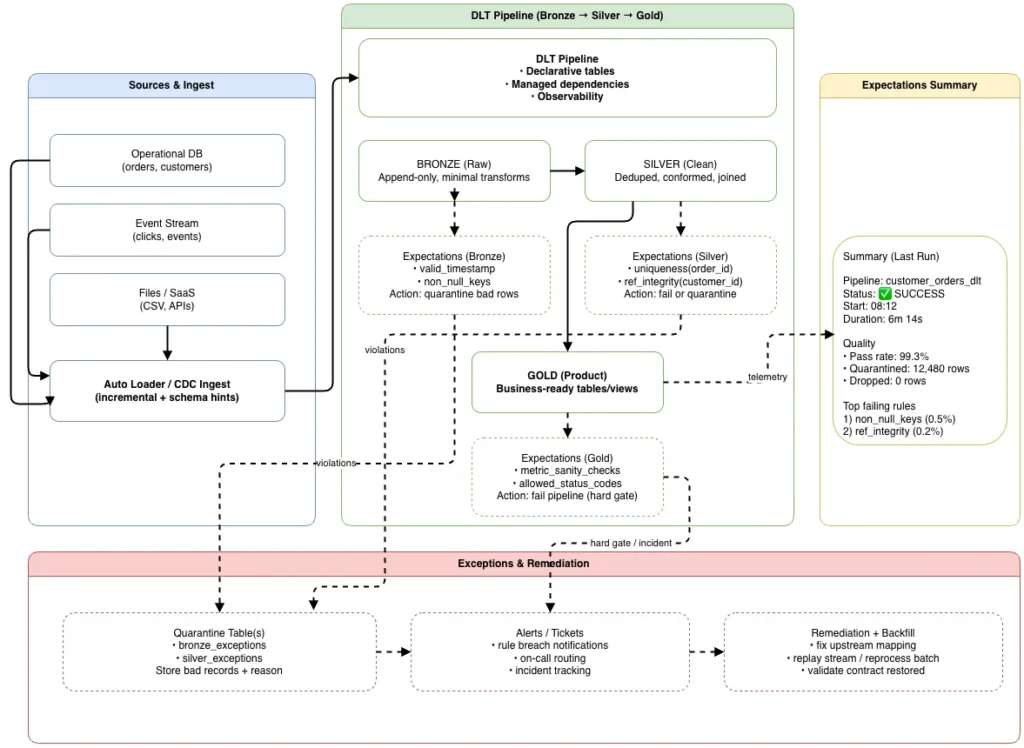
Enforcing Quality with Delta Live Tables (DLT)
One of the most common failure modes is treating data quality as an after-the-fact reporting problem. By the time a dashboard flags bad data, the damage is already done.
Delta Live Tables changes this by enabling quality as code. With DLT Expectations, teams define explicit data quality rules – null thresholds, referential integrity, distribution checks—and enforce them automatically as part of the pipeline itself.
This transforms data quality from:
- A reactive monitoring exercise
into
- A preventative control system
Quality expectations are enforced at each stage of the Bronze–Silver–Gold pipeline, preventing silent data degradation and enforcing data contracts.
From a Data Product perspective, expectations function as data contracts. They ensure that a product is either delivered in a known-good state or not delivered at all. There is no silent degradation.
This is one of the most critical enablers of trust. You cannot scale Data Products without programmatic guarantees.
Data Intelligence Platform (DIQ): Making Products Understandable
Even high-quality data fails if consumers cannot understand it.
The Data Intelligence Platform layer – often referred to as DIQ – addresses the last mile of the Data Product problem: comprehension and discovery. By combining metadata, descriptions, semantics, and AI-assisted search, Databricks enables:
- Natural-language discovery of datasets
- Contextual explanations of fields and metrics
- Reduced dependency on Slack or ticket-based support
Note that this capability fundamentally changes the operating model. Engineers stop acting as human metadata services, and business users gain confidence to self-serve responsibly.
Architectural Patterns for Scalable Data Products
Decoupling Producers and Consumers
Traditional pipeline architectures tightly couple producers and consumers. A schema change in one place ripples across dashboards, ML models, and downstream jobs.
Product-centric architectures introduce deliberate decoupling:
- Producers publish versioned, contract-backed Data Products
- Consumers choose when and how to adopt changes
- Breaking changes become explicit events, not silent failures
A useful mental model is to treat Data Products as internal APIs – stable by default, versioned when necessary, and observable by all stakeholders.
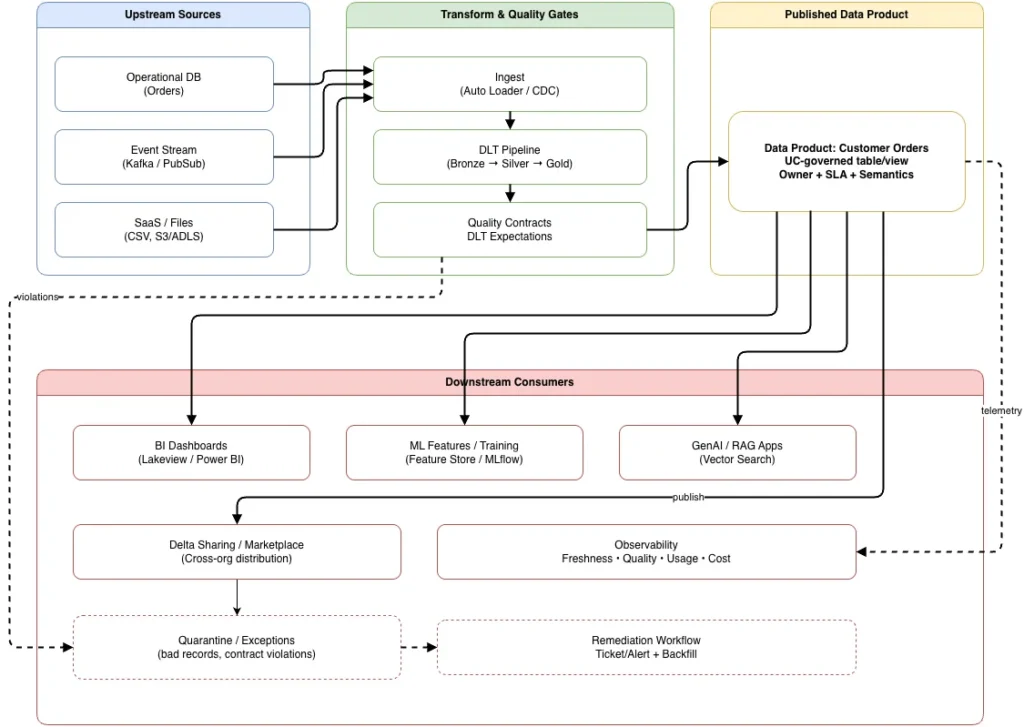
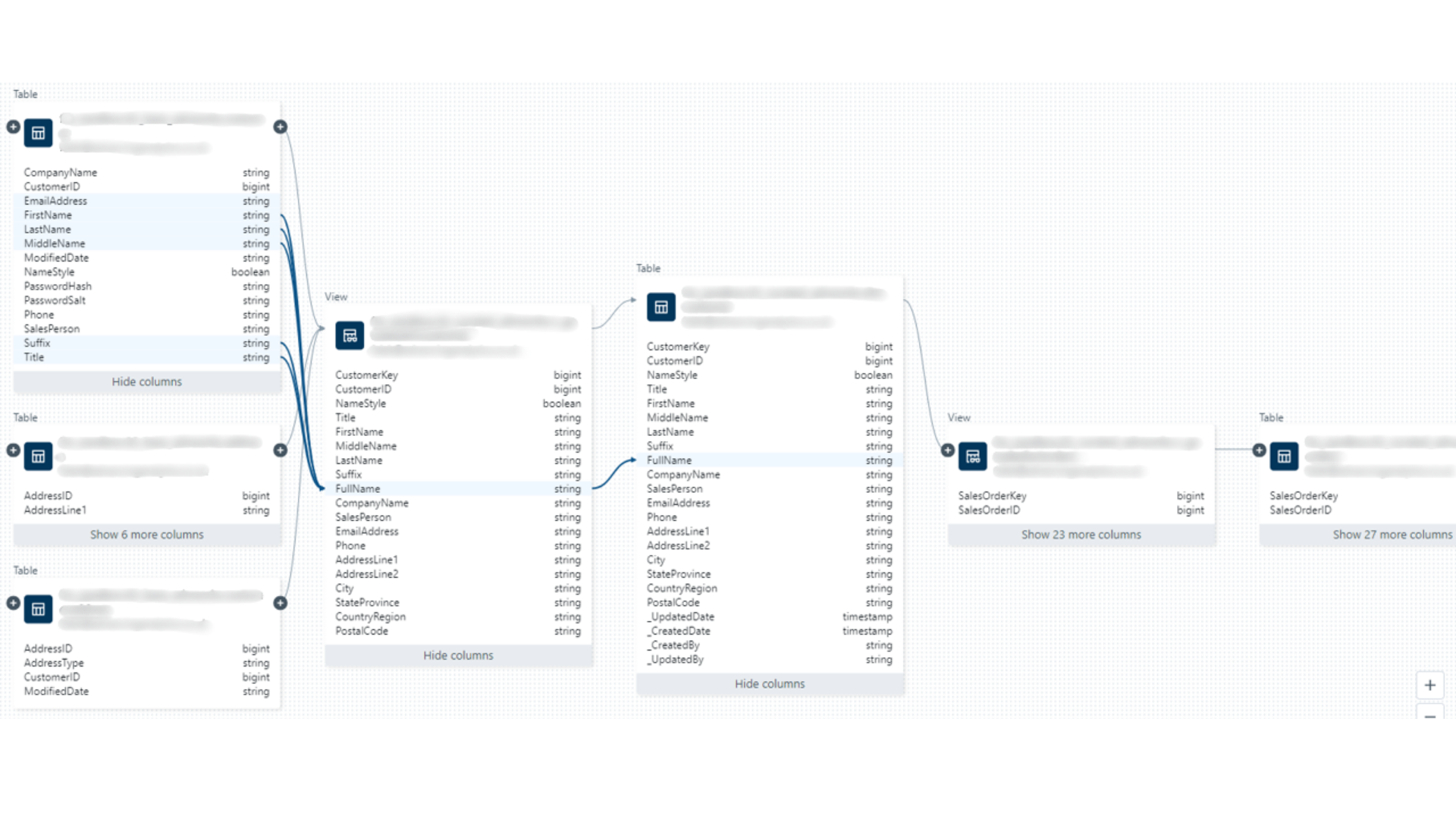
Domain-owned data products are ingested, validated, governed, and published through a unified platform, enabling trusted consumption across BI, ML, and GenAI workloads.
Automation vs. Human Curation
Not everything about Data Products can or should be automated.
We should pursue a pragmatic split:
- Automatable: Lineage capture, quality enforcement, access control, freshness monitoring
- Human-driven: Domain modeling, semantic definitions, lifecycle decisions
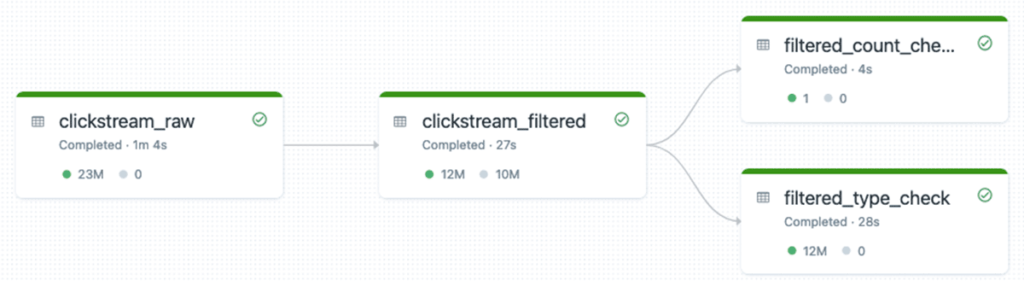
End-to-end lineage and validation steps are automatically captured, improving transparency and operational confidence.
The mistake many teams make is over-rotating on automation without investing in product design. Data Products are engineered artifacts, but they are also designed experiences.
Managing Schema Evolution and Versioning
Schema evolution is one of the most underestimated challenges in product-oriented data architectures. Adding a column is easy; changing a meaning is not.
Effective teams adopt strategies such as:
- Backward-compatible schema evolution by default
- Explicit versioning for breaking changes
- Deprecation windows communicated through metadata and lineage
Without these practices, “data product” becomes just a new name for fragile pipelines.
The Role of Python, Databricks SQL, and dbt
We observe a clear trend: business logic is moving closer to the data and becoming part of the product itself.
Databricks SQL and Python-based DLT pipelines allow teams to:
- Encapsulate transformations alongside quality rules
- Treat logic as governed, versioned assets
- Reduce fragmentation across tools
dbt still plays a role in many environments, but the architectural center of gravity is shifting toward platform-native execution where governance, lineage, and quality are first-class.
Lifecycle and Governance of Data Products
A Data Product does not end at deployment.
The lifecycle is:
- Design: Define domain boundaries, contracts, and success metrics
- Build: Implement transformations, expectations, and metadata
- Publish: Register in Unity Catalog, optionally expose via Delta Sharing
- Monitor: Track freshness, quality, and usage signals
- Evolve or Retire: Invest further – or deprecate based on value
Usage metrics are particularly important. A high-quality product that no one uses is still technical debt. Mature teams actively retire unused products to reduce cognitive and operational load.
Data products evolve through continuous feedback loops driven by quality, usage, and business impact.
Real-World Lessons from the Frontlines
From Pipeline Spaghetti to Domain Products
In one anonymized engagement, I worked with an organization that had accumulated hundreds of interdependent pipelines over several years. Every new analytics request required threading logic through an increasingly fragile graph of jobs. Schema changes routinely broke downstream reports, and GenAI initiatives stalled because no one trusted the underlying data.
The turning point came when the organization reorganized around domain-owned Data Products. Each domain published a small number of high-value products with explicit contracts, enforced via DLT, and governed through Unity Catalog. Downstream teams shifted from scraping intermediate tables to consuming stable products.
The result was not just technical improvement – it was organizational clarity. Teams knew what they owned, what they depended on, and what mattered.
The Risk of Standing Still in 2025+
Organizations that remain locked in monolithic ETL architectures face growing risks:
- Fragile analytics that cannot tolerate change
- Governance gaps that block AI adoption
- Inability to safely operationalize GenAI or advanced ML
Without strong governance and trusted Data Products, AI initiatives become high-risk experiments rather than scalable capabilities.
One Piece of Advice for CTOs
If asked to give a single piece of advice to a CTO modernizing their data estate next month, I do not start with pipelines, tools, or models, but rather:
Invest in governance first.
Unity Catalog is not an optional add-on; it is the prerequisite for scale, trust, and AI readiness. Without it, organizations may modernize their infrastructure – but they will still end up with a more expensive legacy swamp.
Conclusion: From Movement to Meaning
Beyond 2025, data engineering is no longer about how efficiently data moves. It is about how reliably it delivers value.
The shift from pipelines to Data Products requires new metrics, new architectures, and new habits. With the Databricks Data Intelligence Platform – anchored by Unity Catalog, Delta Live Tables, and built-in intelligence – this shift is not only possible, but practical.
For data leaders, the question is no longer whether to adopt Data Products – but how quickly they can make trust, governance, and value the default.
If your organization is evaluating its data maturity or exploring a Data Products Strategy on Databricks, consider engaging with a consulting team for a structured assessment or architecture workshop to identify where pipeline thinking is holding you back – and how to move forward with confidence.


