 Data Engineering
Data Engineering  Data Strategy + Governance
Data Strategy + Governance  Data Migrations
Data Migrations  Concierge + Support
Concierge + Support  Artificial Intelligence
Artificial Intelligence  Training + Enablement
Training + Enablement  Data Analytics + Insights
Data Analytics + Insights  Financial Services
Financial Services  Communications, Media + Entertainment
Communications, Media + Entertainment  Healthcare + Life Sciences
Healthcare + Life Sciences  Technology + Digital Natives
Technology + Digital Natives  Manufacturing + Automotive
Manufacturing + Automotive  Public Sector
Public Sector  Retail + Consumer Goods
Retail + Consumer Goods  Race to the Lakehouse
Race to the Lakehouse  AI + Data Maturity Assessment
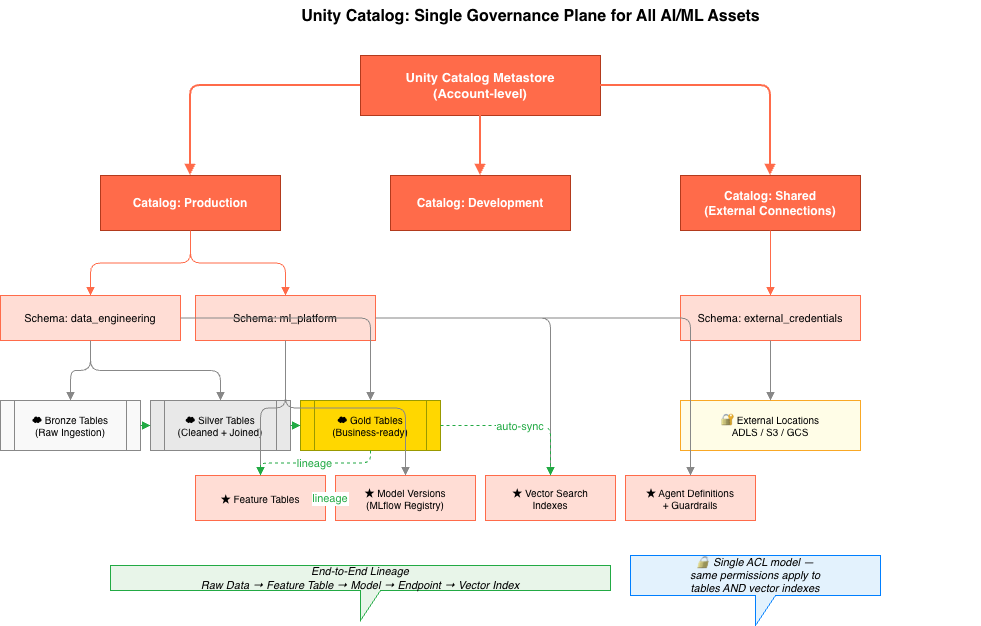
AI + Data Maturity Assessment  Unity Catalog
Unity Catalog  Rapid GenAI
Rapid GenAI  Modern Data Connectivity
Modern Data Connectivity  Gatehouse Security
Gatehouse Security  Health Check
Health Check  Sample Use Case Library
Sample Use Case Library  Blog
Blog  Events
Events  About Us
About Us  Careers
Careers  Founding Team
Founding Team 
This is an environment problem, not a code problem. And in our experience working with healthcare and life sciences organizations on Databricks, it’s also a business problem: when pipelines are fragile, the Gold layer that feeds your Genie spaces becomes unreliable, and the self-service analytics your clinical and finance teams depend on starts generating questions about data quality instead of insights.
The fix is containerization, and what most teams don’t fully appreciate is that Databricks is already built on Kubernetes. Genie, Lakebase, Model Serving, Agent Bricks: every major platform capability is containerized by design. The question isn’t whether to use containers. It’s whether you’re taking enough control of the container layer to make your data platform production-grade.
This post walks through how Kubernetes underpins the Databricks Data Intelligence Platform, how the capabilities your business stakeholders care about, Genie for self-service analytics, Lakebase for operational applications, depend on that infrastructure, and what we’ve learned building this stack for HLS clients in production.
The Databricks Platform Is Already Containerized
When you launch a Databricks cluster, you’re launching Kubernetes pods. Spark driver and executor processes run as containers orchestrated by K8s. Serverless compute spins up containerized runtimes in seconds and scales to zero when idle. Model Serving deploys ML endpoints as containerized REST services with sub-2-minute deploy times and GPU-aware batching built in. Agent Bricks runs multi-step agentic AI workflows as containerized execution graphs with tracing and guardrails.
Understanding this matters because it explains how the platform’s highest-value capabilities work:
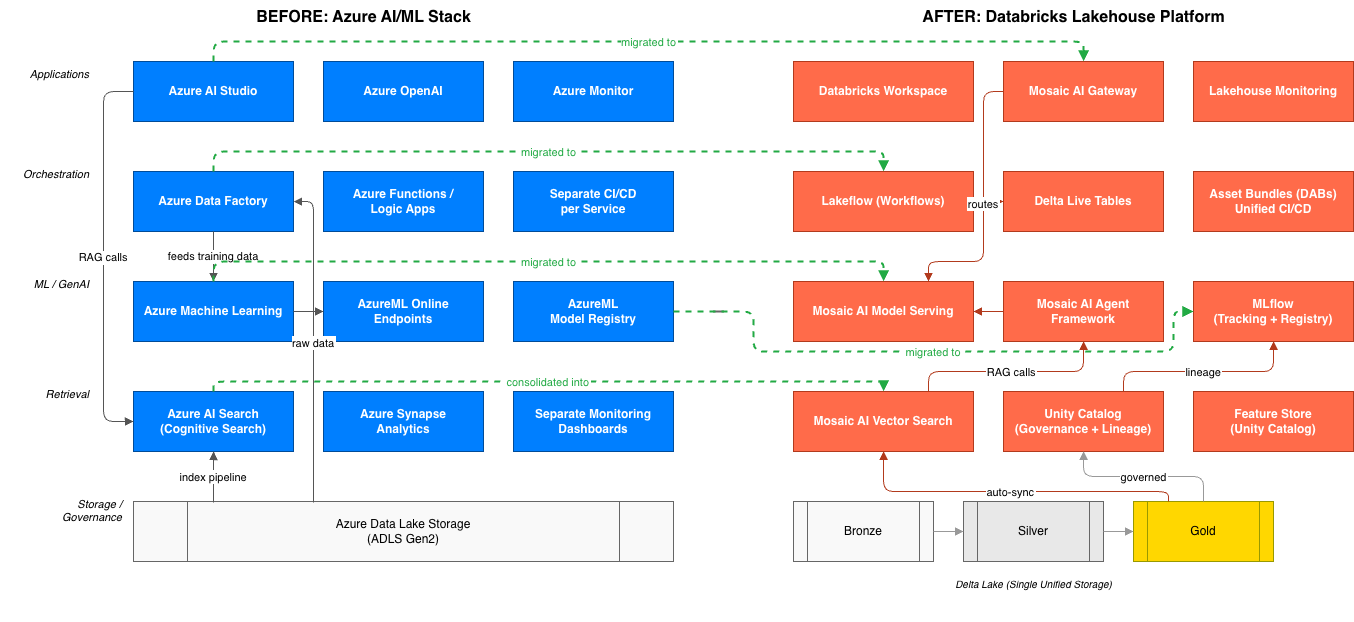
Genie and the AI/BI Layer
Genie, Databricks’ natural language analytics interface, runs containerized NLP inference against the semantic models and metric views defined in your AI/BI layer. When a store manager or a clinical analyst asks a natural language question in a Genie space, that query is processed by a containerized inference runtime that understands the business glossary, the curated SQL patterns, and the governance boundaries you’ve defined in Unity Catalog.
The business value of Genie is real, but it’s directly dependent on what’s beneath it: a clean, governed Gold layer with clearly defined metrics. Containerized ingestion pipelines that run consistently, with pinned dependencies and environment parity across dev and prod, are what make that Gold layer trustworthy. When the infrastructure is sloppy, Genie surfaces wrong answers. When it’s solid, Genie delivers genuine self-service.
Lakebase: Closing the OLTP/OLAP Gap
The traditional enterprise data architecture requires two separate systems: a transactional database (Postgres, MySQL, Oracle) for operational applications that need <10ms latency and ACID transactions, and a lakehouse for analytical workloads. These systems have historically lived in separate worlds, synchronized imperfectly through ETL processes that are themselves a source of environment drift.
Lakebase changes this. It’s a fully managed, serverless Postgres database that runs inside the Databricks security perimeter and automatically syncs data to and from the lakehouse. Full Postgres SQL engine, sub-10ms latency, ACID transactions, autoscaling, scale-to-zero when idle, and your operational data is already in the same governance boundary as your analytical data. For HLS organizations, this means credentialing systems, member portals, and care management applications can run on the same platform as your population health analytics, with Unity Catalog governing access across both.
Unity Catalog: Governance Across Everything
Unity Catalog sits across all containerized compute as the governance layer. It doesn’t care whether your pipeline runs in a classic cluster, a serverless job, a Model Serving endpoint, or a Lakebase-connected application, lineage, access control, and audit logs are enforced at the data and model level. This decoupling of governance from compute is what makes container portability possible in regulated environments. You can change your runtime without changing your compliance posture.
From Data Engineering to Business Insight: The Medallion + Genie Pattern
Across our HLS engagements, the most impactful implementations follow a consistent architecture: containerized ingestion pipelines that build a clean medallion foundation, Unity Catalog for governance, and Genie on top to put self-service analytics in the hands of the people who need it.
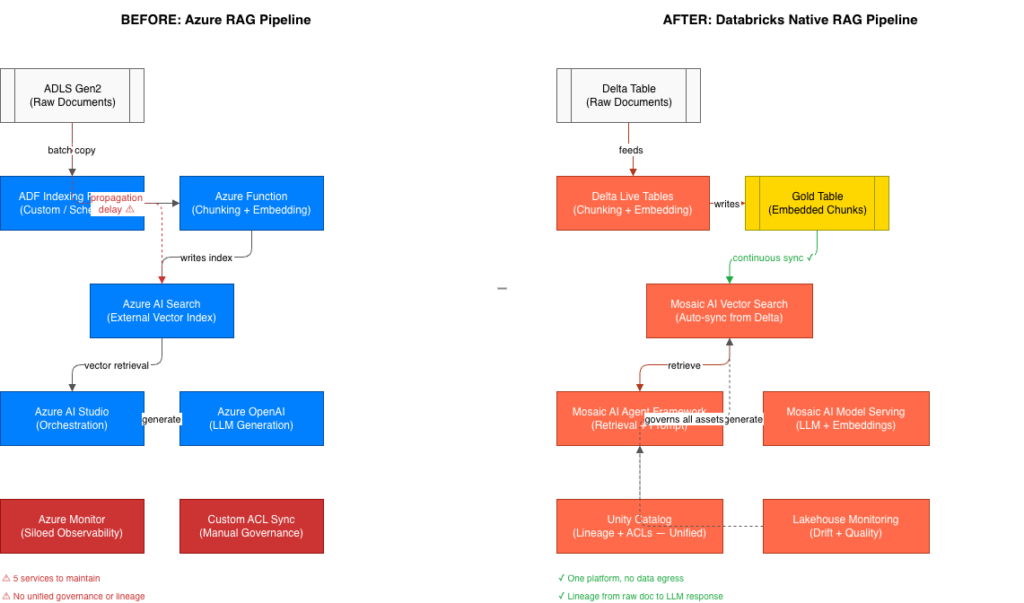
Building the Foundation
The Bronze → Silver → Gold medallion pattern maps naturally to containerized pipeline stages. Each layer has a different dependency profile: Bronze ingestion jobs need source system connectors and parsers; Silver transformation jobs need data quality libraries and normalization tooling; Gold serving layers need output formatters aligned to the business metrics Genie will query against. Maintaining separate container images per layer – each with minimal dependencies, each built reproducibly in CI – means environment changes are scoped, security scanning is tractable, and promotions from dev to prod are deterministic.
| CLIENT SPOTLIGHT: REGIONAL HEALTHCARE EDW A leading regional health system consolidated data from Epic Clarity and Caboodle, Google BigQuery, MySQL, and Informatica onto Databricks as their Enterprise Data Warehouse. Entrada built the medallion architecture across Patient, Provider, Physician, and Location data segments, addressing data quality and normalization at the Silver layer. Once the Gold layer was established, Genie was enabled organization-wide – giving clinical teams, finance, and operations self-service access to reporting without routing requests through the data engineering team. Results: org-wide self-service enablement, reduced technology sprawl, and a faster path to AI-driven use cases. |
What enabled Genie to deliver accurate results in this environment was the work that happened before any business user asked a question: a well-defined business glossary, curated SQL query templates that served as training examples for Genie’s reasoning, and detailed instruction sets for common operational scenarios. Getting that right is an investment, but it’s what separates a Genie space that builds trust from one that generates skepticism.
On a separate engagement with an ACO health organization, we followed the same architecture pattern, migrating reports and dashboards from JasperSoft to PowerBI while simultaneously enabling Genie for population health analytics. The ability to ask natural language questions against population health, care quality, and billing data, without waiting for analyst bandwidth, directly reduced the BI request backlog and gave clinical leadership faster access to care management insights.
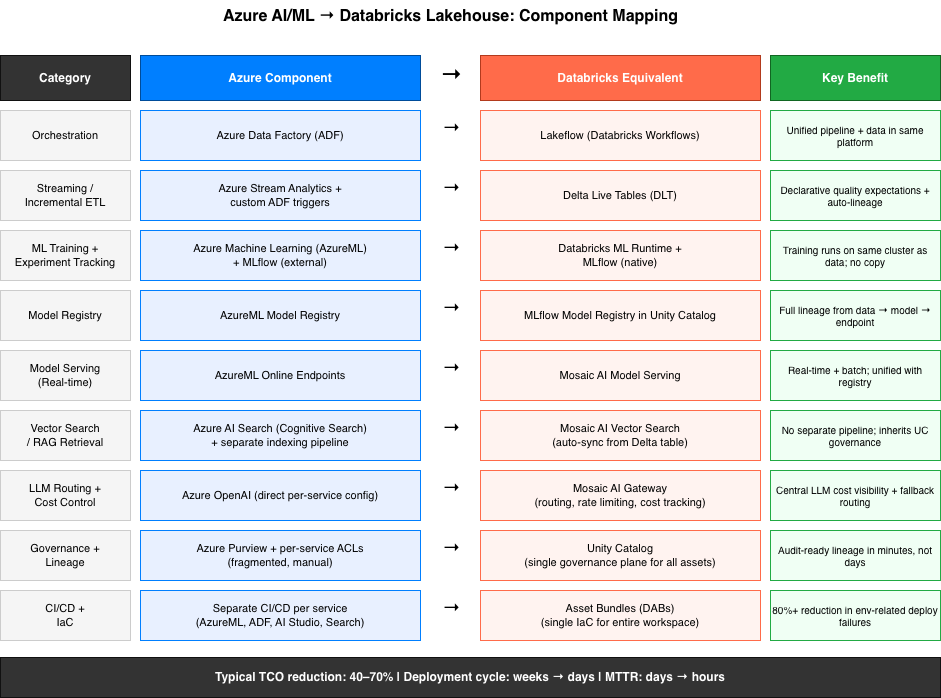
Containerized AI/ML Pipelines: From Training to Production
The same container discipline that produces reliable data pipelines is even more critical for ML workloads. A model trained in an environment that can’t be exactly reproduced six months later is a compliance liability in healthcare. A fine-tuned LLM deployed against clinical data needs to have a verifiable, immutable record of exactly which training data, which model weights, and which inference runtime produced its outputs.
Custom Container Images for Regulated ML
Databricks supports custom Docker base images on clusters, which is where teams move from “managed environment” to “reproducible infrastructure.” Init scripts are useful for lightweight additions, but they run at cluster startup on top of Databricks’ base runtime and can drift when the base image changes. Custom container images move dependency specification into the build step: your Dockerfile pins every system library, Python version, and ML framework dependency. The resulting image is immutable.
"docker": {
"url": "your-registry.azurecr.io/hls-ml-training:v2.1.0",
"basic_auth": {
"username": "{{secrets/docker/acr-username}}",
"password": "{{secrets/docker/acr-password}}"
}
}The image tag is pinned to a specific build. Promoting a pipeline from development to production means updating the cluster policy reference to point to a production-tagged image, the code doesn’t change, the environment doesn’t change, what changes is which orchestrator targets it. When a compliance team asks “what software version processed this dataset?” the answer is a container image SHA in Unity Catalog.
| CLIENT SPOTLIGHT: CLINICAL TRIAL PATIENT IDENTIFICATION A healthcare analytics firm partnered with Entrada to build a knowledge graph on Databricks for processing unstructured clinical notes and identifying clinical trial candidates. Entrada built a scalable data architecture on Databricks, fine-tuned a domain-specific LLM (GatorTron and ClinicalBERT) against the firm’s clinical data, and implemented NLP pipelines for parsing diagnosis information. Unity Catalog provided governance and data security throughout. Results: patient identification and selection time reduced from 17 hours per patient to minutes, 100% recall on true positive recognition, 82%+ accuracy for diagnosis extraction. |
On a separate disease prediction platform engagement, Entrada built a full data pipeline spanning sources including Epic, Oracle HIE, Oracle SQL Server, NextGate, and Virtual Health, processing patient, clinical, payer, and provider data through the medallion architecture. MLflow and Mosaic AI powered the disease prediction models, with population health dashboards, care quality metrics, and billing analytics surfaced in PowerBI. The platform is now being used for early intervention programs targeting disease prevention.
Both projects required environment reproducibility that init scripts couldn’t provide. Custom container images, scoped per pipeline stage, gave the compliance and data science teams the auditability and environment parity they needed.
Lakebase: When the Operational Database Lives on the Lakehouse
Most enterprise data architectures carry technical debt that’s easy to miss until it becomes expensive: operational systems and analytical systems live on completely different infrastructure, synchronized through ETL processes that themselves require maintenance, monitoring, and environment management.
For HLS organizations, this is particularly acute. A credentialing application might run on RDS Postgres. The population health analytics platform runs on Databricks. Member engagement data lives in a separate operational store. Each system has its own security perimeter, its own backup regime, its own set of operational concerns, and any data that needs to cross boundaries has to be moved, which introduces latency, errors, and governance gaps.
Lakebase addresses this directly. As a fully managed, serverless Postgres database running inside the Databricks platform, it delivers sub-10ms latency and ACID transactions for operational applications while automatically syncing data to the lakehouse for analytics. It supports the full Postgres ecosystem, extensions including PostGIS and pgvector, standard drivers and tools, and all the SQL semantics your application developers expect, while living in the same governance boundary as your Databricks analytical workloads.
| CLIENT SPOTLIGHT: LEADING DIGITAL HEALTH CLINIC – POSTGRES TO DATABRICKS A leading digital health platform, which combines expert clinical care with advanced technology to go beyond traditional physical therapy, partnered with Entrada to migrate critical infrastructure from Postgres to Databricks. Entrada migrated over 2,000 processes, including data pipelines, jobs, and workflows. Results: increased pipeline scalability and processing speed, reduced maintenance cost, and a platform foundation that supports both operational and analytical workloads without separate infrastructure. |
For HLS teams planning new applications, credentialing portals, care management tools, member engagement systems, Lakebase removes the architectural decision between operational database and lakehouse. Applications that need transactional consistency can be built on Lakebase, with their data automatically available for population health analytics, Genie queries, and ML pipelines running alongside them on the same platform.
What Engineers Should Do Right Now
The capabilities described in this post, Genie for self-service analytics, Lakebase for operational applications, containerized ML pipelines for regulated workloads, are all available on Databricks today. The infrastructure to support them is already running. The question is how deliberately you’re managing it.
A few concrete starting points:
- Audit one ingestion pipeline for environment drift. If it’s relying on init scripts for critical dependencies, containerize it. Pin the image. Build a promotion workflow from dev to prod that doesn’t require manual steps.
- Evaluate Genie against your Gold layer before adding another BI tool. The prerequisites, a business glossary, curated query examples, defined metric views, are engineering work, but they’re worth doing once correctly rather than building another point tool on top of shaky semantics.
- Identify one operational database that could consolidate to Lakebase. If it’s Postgres, the migration path is direct. If it’s a workload where analytical access to operational data causes pain, Lakebase’s automatic lakehouse sync is the answer.
- Instrument Unity Catalog lineage on your ML pipelines. Container image SHAs, training dataset versions, and model artifacts should all be captured in Unity Catalog. This is what makes regulated ML auditable.
The teams that get the most out of Databricks aren’t the ones with the most features turned on, they’re the ones who’ve built a disciplined foundation that the platform’s capabilities can be trusted to run on.
Working With Entrada
Entrada is a Databricks partner specializing in healthcare and life sciences data platforms. We design and deliver medallion architectures, Genie implementations, ML pipelines, and Lakebase migrations for HLS organizations, from regional health systems to global life sciences companies.
The projects described in this post are representative of what we build: production systems with real governance requirements, real compliance constraints, and real business users depending on the data being right.
Ready to talk about your data platform? Contact our team.


