 Data Engineering
Data Engineering  Data Strategy + Governance
Data Strategy + Governance  Data Migrations
Data Migrations  Concierge + Support
Concierge + Support  Artificial Intelligence
Artificial Intelligence  Training + Enablement
Training + Enablement  Data Analytics + Insights
Data Analytics + Insights  Financial Services
Financial Services  Communications, Media + Entertainment
Communications, Media + Entertainment  Healthcare + Life Sciences
Healthcare + Life Sciences  Technology + Digital Natives
Technology + Digital Natives  Manufacturing + Automotive
Manufacturing + Automotive  Public Sector
Public Sector  Retail + Consumer Goods
Retail + Consumer Goods  Race to the Lakehouse
Race to the Lakehouse  AI + Data Maturity Assessment
AI + Data Maturity Assessment  Unity Catalog
Unity Catalog  Rapid GenAI
Rapid GenAI  Modern Data Connectivity
Modern Data Connectivity  Gatehouse Security
Gatehouse Security  Health Check
Health Check  Sample Use Case Library
Sample Use Case Library  Blog
Blog  Events
Events  About Us
About Us  Careers
Careers  Founding Team
Founding Team 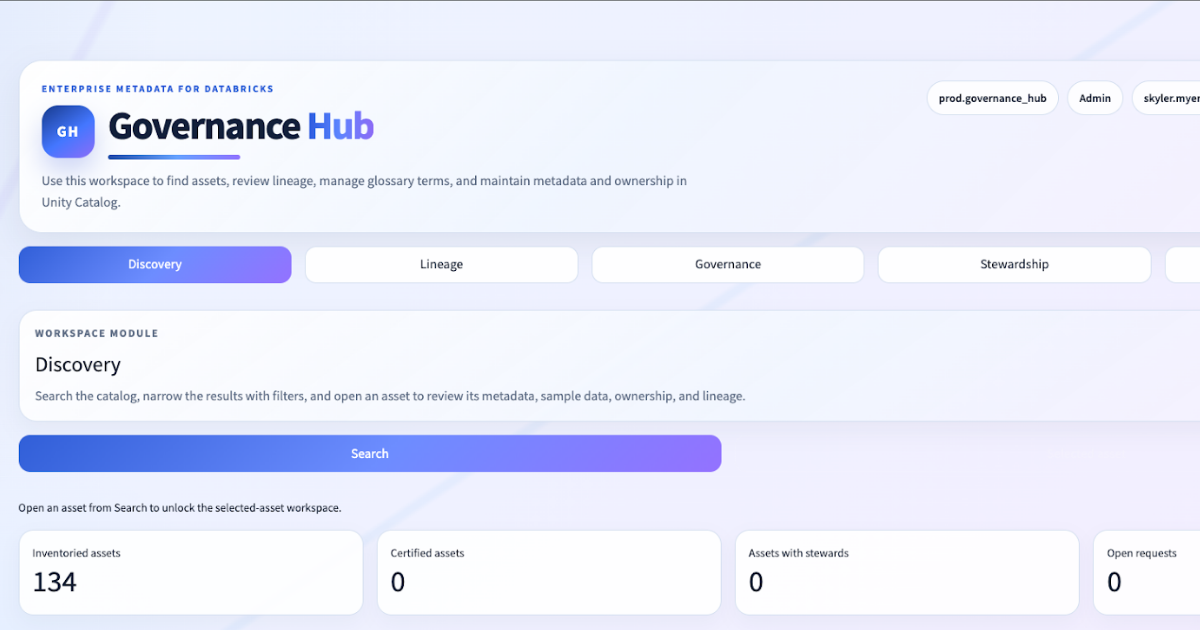
That gap is exactly why we built the Governance Hub.
Governance Hub is a workspace-portable Databricks App accelerator that we can install directly into a client workspace. It is designed to make Databricks feel less like “the place where the data lives” and more like “the place where the governance product lives.” It takes the interaction bar set by tools like OpenMetadata and DataHub, then reinterprets that experience inside the Databricks control plane, using Unity Catalog system metadata, Databricks SQL, Delta-backed governance state, and Databricks Asset Bundles.
This is not a dashboard. It is not a lightweight helper UI. It is not a proof-of-concept that punts the hard parts to some future roadmap.
It is an opinionated governance accelerator that gives clients a mature discovery, lineage, glossary, and stewardship experience immediately in their own workspace.
The Real Problem We Were Solving
Databricks is already excellent at the physical metadata plane:
- Unity Catalog knows your catalogs, schemas, tables, columns, comments, and tags.
- System tables know your table and column lineage.
- Databricks Apps gives us a secure, SSO-authenticated application surface directly inside the platform.
- Databricks Asset Bundles gives us reproducible deployment and promotion across environments.
But for governance leaders, that still leaves a major gap.
The physical metadata is there, but the governance product experience is not.
Most organizations do not want governance users jumping between:
- Unity Catalog metadata screens
- SharePoint folders
- external catalogs
- change-request spreadsheets
- Power BI governance scorecards
- ad hoc stewardship processes
They want a centralized operating layer for governance. They want discovery to feel intentional. They want lineage to be readable and actionable. They want glossary, ownership, and metadata quality workflows to sit on top of the actual lakehouse assets, not beside them.
That was the product mandate we worked against on this project:
- prioritize Discovery, Lineage, and Governance
- make the experience feel like an internal enterprise metadata product
- deliver value on top of Databricks, not just duplicate what Databricks already provides
- keep it installable in a client workspace with minimal friction
Why We Built This Inside Databricks
A lot of governance solutions fail because they create a second metadata universe.
The moment governance definitions, lineage views, owner assignments, and approval workflows live outside the platform where the data work happens, the clock starts ticking on drift:
- the glossary says one thing
- the table comment says another
- the lineage UI is not the lineage the engineers trust
- change workflows are disconnected from the physical asset surface
We wanted the opposite.
We wanted a governance experience where:
- the source of operational truth is still Unity Catalog metadata and system tables
- the governance control plane lives natively in Databricks
- the app surface is deployable as a first-class Databricks App
- the solution is portable across client workspaces through DABs
- optional extensions like OpenMetadata can be bridged in, but are not required
That leads to a very different architecture from the usual governance platform pattern.
The Architecture: Native App, Native Metadata, Native State
At a high level, Governance Hub has three major layers:
1. Presentation layer
- Streamlit-based Databricks App
- Enterprise metadata-product shell
- Discovery, lineage, governance, stewardship, and admin modules
2. Metadata access layer
- Databricks SQL Warehouse
- Unity Catalog
information_schema system.access.table_lineagesystem.access.column_lineage
3. Governance state layer
- Delta tables stored inside a dedicated governance schema
- roles, glossary terms, data owners, asset links, change requests
No Kafka, no Elasticsearch, no Docker – just a SQL Warehouse and this app.
That simplicity is not accidental. It is one of the biggest strengths of the accelerator.
Deployment Model: Installable as an Accelerator
From the beginning, we treated this as something Entrada could install in client workspaces immediately, not just as a one-off internal prototype.
That is why the deployment model is built around Databricks Asset Bundles and a Databricks App resource in databricks.yml.
There are two things worth calling out here for Databricks practitioners.
First, this is not “Databricks as backend, external app as frontend.” This is Databricks as the frontend runtime too.
Second, this is not a fragile deploy story. It is an accelerator with an environment model, variable injection, warehouse binding, and reproducible promotion.
For clients, that matters because it turns a governance concept into something operational:
- clone
- set a few variables and secrets
- deploy with `databricks bundle deploy`
- bootstrap governance state on first launch
That is a very different conversation from “buy a catalog platform and spend six months integrating it.”
A Governance Control Plane Built in Delta
A lot of teams reach for a separate service the moment they need mutable governance state.
We did not.
Instead, we built a Delta-backed governance control plane inside a dedicated Unity Catalog schema. The GovernanceStore class is the center of that design.
We create and manage:
user_rolesglossary_termsdata_ownersasset_linkschange_requests
This is a subtle but important design decision.
We did not build “just a UI” on top of Unity Catalog. We built a governance product with its own operating state, but we kept that state inside the same platform boundary as the assets it governs.
That gives clients:
- simpler operations
- simpler security
- simpler backup/recovery posture
- less integration drift
- less total cost
It also means the control plane is SQL-native. Upserts are handled with MERGE, not an external ORM/service layer.
That pattern repeats across glossary terms, asset links, and owners. For a Databricks-native governance accelerator, this is exactly the kind of operational simplicity we want.
The Metadata Access Layer: Statement Execution Done Properly
We intentionally kept metadata access in one place: govhub/uc.py.
That matters because metadata apps fail quickly when metadata retrieval logic gets duplicated across the UI layer. We built a dedicated UCSQLClient around the Databricks Statement Execution API and had it return pandas DataFrames consistently to the rest of the app.
There are a few technical wins here.
1. We normalized the API surface
The UI does not care whether the query is hitting information_schema, SHOW TABLES, or a system lineage table. It gets DataFrames back.
2. We handled the real-world messiness of statement execution
The Databricks SDK can return typed objects or dict-like payloads depending on context. We normalized nested access with _get() and normalized statement state handling with _state_str().
3. We respected Databricks as the execution plane
We did not mirror metadata into a second search engine or stand up a separate query service just to drive the app. The warehouse is the query plane.
That keeps the solution aligned with client operations and security posture.
Turning Raw Unity Catalog Metadata Into a Product-Grade Discovery Index
One of the most interesting parts of this project is that the discovery experience is not backed by a separate indexing engine. It is assembled dynamically from Unity Catalog metadata plus governance state.
The heart of that work is _cached_asset_inventory() in app.py.
This function does much more than list tables.
It:
- enumerates catalogs
- gathers table inventory from
information_schema.tables - gathers tags from
information_schema.table_tags - filters out noisy/system-generated assets
- merges governance owner assignments
- merges asset links
- rolls up change request counts
- computes governance score and status
- synthesizes a search corpus
Here is the key shape:
Python:
@st.cache_data(ttl=_META_TTL, show_spinner=False)
def _cached_asset_inventory(_uc: UCSQLClient, _store: GovernanceStore) -> pd.DataFrame:
catalogs = _cached_catalogs(_uc)
inventory_frames: List[pd.DataFrame] = []
tag_maps: Dict[str, Dict[str, str]] = {}
for catalog in catalogs:
inv = _cached_catalog_inventory(_uc, catalog)
if not inv.empty:
inv = inv.copy()
inv["comment"] = inv["comment"].map(_normalize_str)
inv["fqn"] = (
inv["table_catalog"].astype(str)
+ "."
+ inv["table_schema"].astype(str)
+ "."
+ inv["table_name"].astype(str)
)
inventory_frames.append(inv)Then the enrichment layers come in:
Python:
inventory["domain"] = inventory["tags"].map(
lambda tags: _tag_value(tags if isinstance(tags, dict) else {}, "domain")
)
inventory["tier"] = inventory["tags"].map(
lambda tags: _tag_value(tags if isinstance(tags, dict) else {}, "tier")
)
inventory["certification"] = inventory["tags"].map(
lambda tags: _tag_value(tags if isinstance(tags, dict) else {}, "certification")
)And the governance score is computed directly from asset state:
Python:
inventory["governance_score"] = (
35 * inventory["comment"].ne("").astype(int)
+ 20 * inventory["owner_count"].gt(0).astype(int)
+ 15 * inventory["domain"].ne("").astype(int)
+ 15 * inventory["certification"].ne("").astype(int)
+ 15 * inventory["glossary_term"].ne("").astype(int)
)
inventory["governance_status"] = "Needs Work"
inventory.loc[inventory["governance_score"] >= 55, "governance_status"] = (
"Operational"
)
inventory.loc[inventory["governance_score"] >= 80, "governance_status"] = (
"Enterprise Ready"
)Here is the key shape:
Python:
@st.cache_data(ttl=_META_TTL, show_spinner=False)
def _cached_asset_inventory(_uc: UCSQLClient, _store: GovernanceStore) -> pd.DataFrame:
catalogs = _cached_catalogs(_uc)
inventory_frames: List[pd.DataFrame] = []
tag_maps: Dict[str, Dict[str, str]] = {}
for catalog in catalogs:
inv = _cached_catalog_inventory(_uc, catalog)
if not inv.empty:
inv = inv.copy()
inv["comment"] = inv["comment"].map(_normalize_str)
inv["fqn"] = (
inv["table_catalog"].astype(str)
+ "."
+ inv["table_schema"].astype(str)
+ "."
+ inv["table_name"].astype(str)
)
inventory_frames.append(inv)Then the enrichment layers come in:
Python:
inventory["domain"] = inventory["tags"].map(
lambda tags: _tag_value(tags if isinstance(tags, dict) else {}, "domain")
)
inventory["tier"] = inventory["tags"].map(
lambda tags: _tag_value(tags if isinstance(tags, dict) else {}, "tier")
)
inventory["certification"] = inventory["tags"].map(
lambda tags: _tag_value(tags if isinstance(tags, dict) else {}, "certification")
)And the governance score is computed directly from asset state:
Python:
inventory["governance_score"] = (
35 * inventory["comment"].ne("").astype(int)
+ 20 * inventory["owner_count"].gt(0).astype(int)
+ 15 * inventory["domain"].ne("").astype(int)
+ 15 * inventory["certification"].ne("").astype(int)
+ 15 * inventory["glossary_term"].ne("").astype(int)
)
inventory["governance_status"] = "Needs Work"
inventory.loc[inventory["governance_score"] >= 55, "governance_status"] = (
"Operational"
)
inventory.loc[inventory["governance_score"] >= 80, "governance_status"] = (
"Enterprise Ready"
)That is the key pattern to notice: we are deriving governance posture from native platform state, not merely presenting metadata.
This is where the accelerator stops being a UI and starts becoming an operating model.
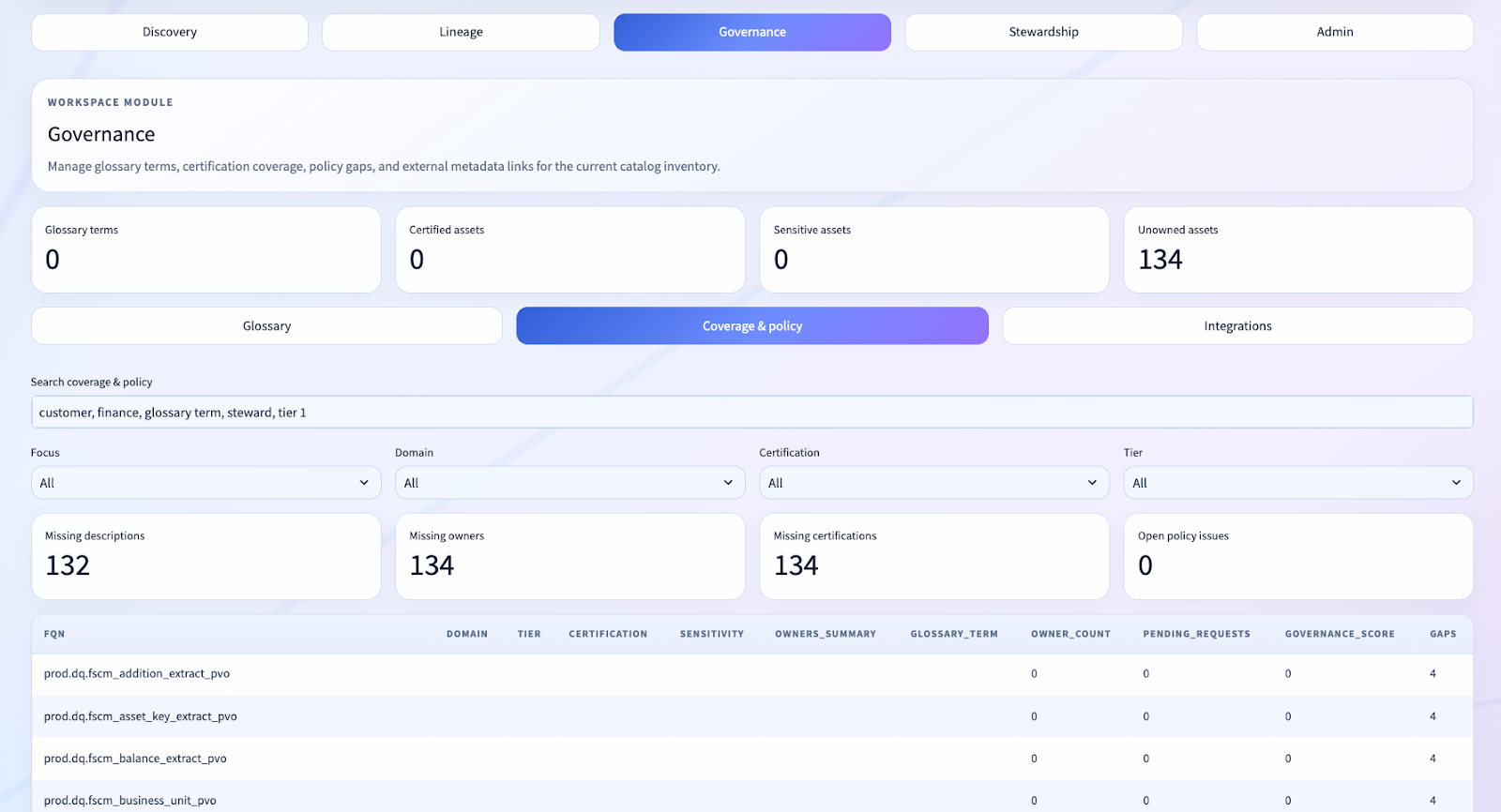
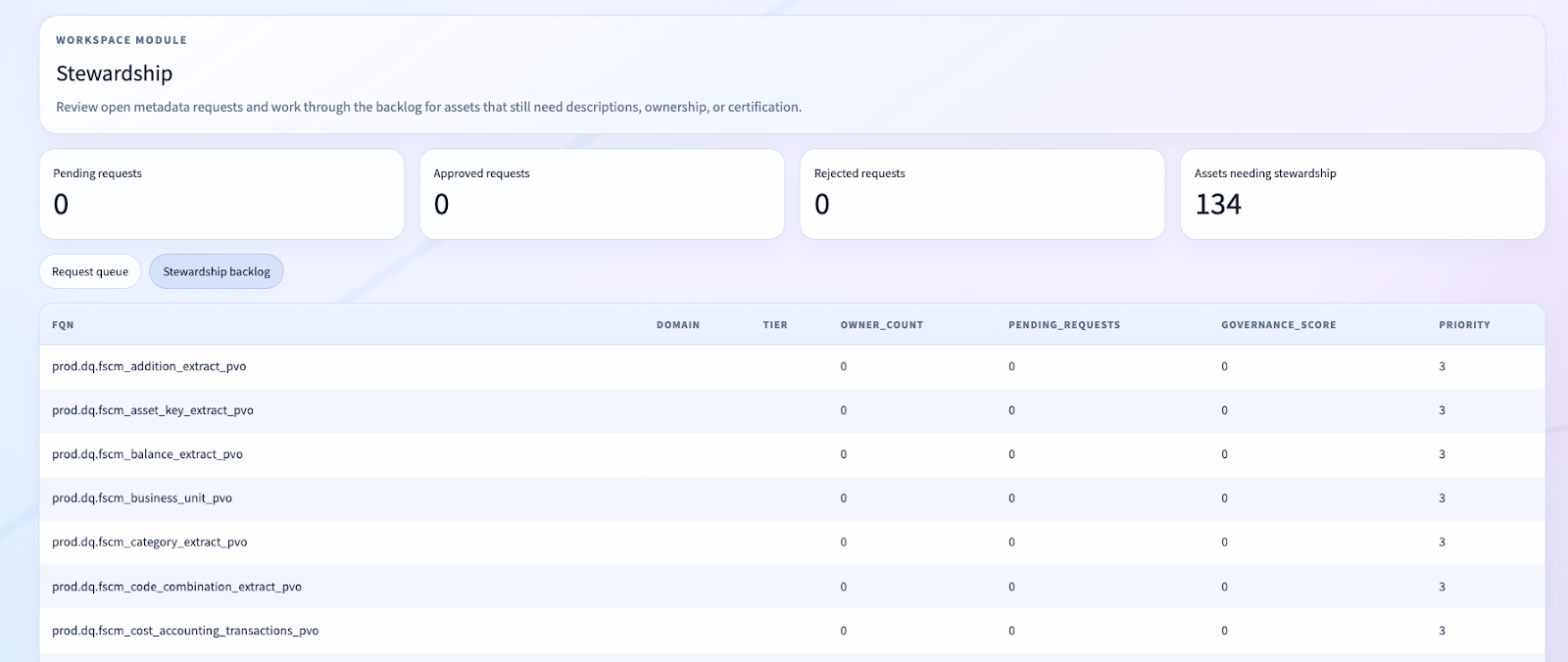
Filtering the Noise: Why Trust Matters in Governance UX
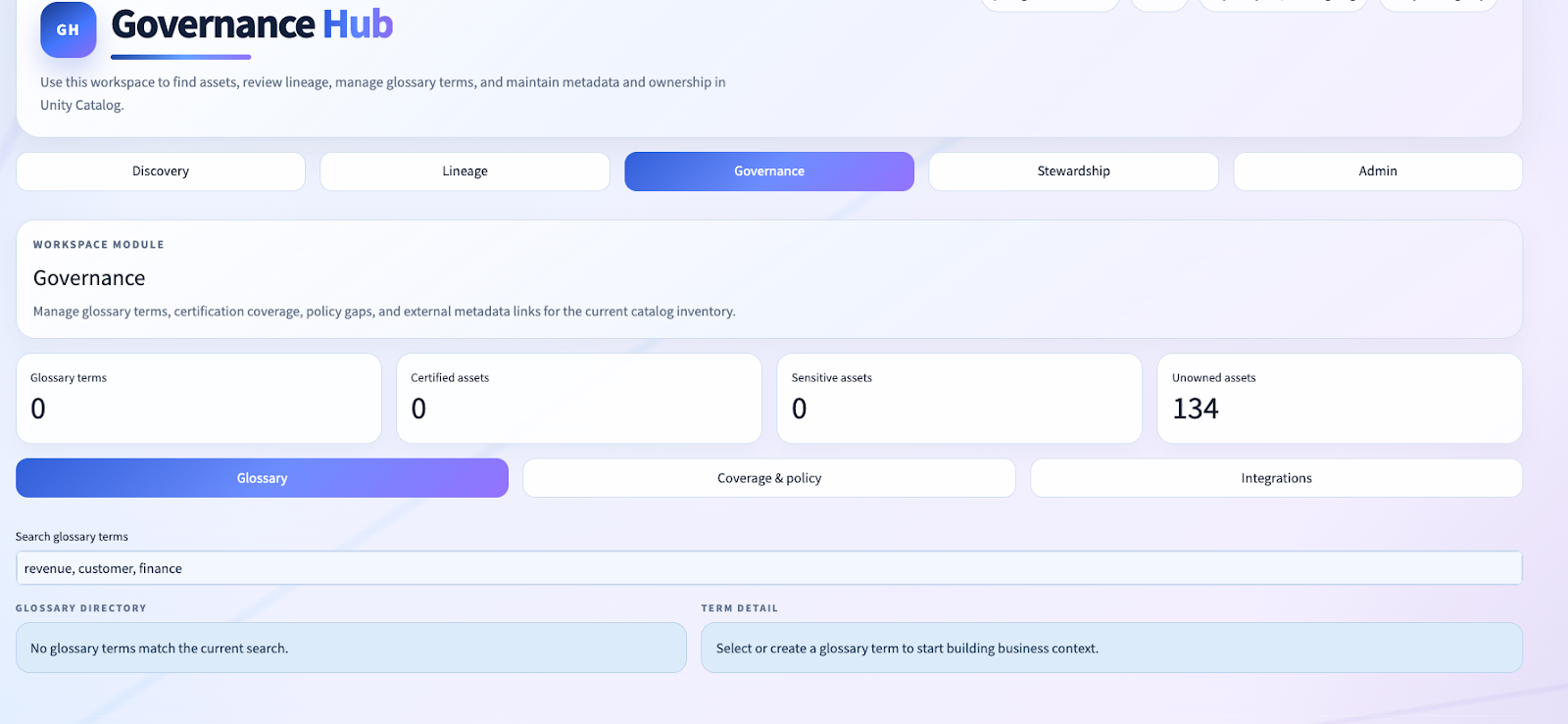
One of the lessons from this repo is that governance UX is not only about what you show. It is also about what you refuse to show.
In live lakehouse environments, catalogs can be full of noisy or system-generated assets. If those flood the discovery or lineage experience, user trust collapses immediately.
That is why we introduced shared asset filtering logic, including exclusions for SDP materialization tables and self-lineage.
This is not cosmetic cleanup. It is a core product decision.
When a governance lead opens a lineage workspace, they need to see the lineage that matters, not machine-generated noise that makes the tool feel unserious.
That principle now lives in repo guidance as well:
- filter noisy/system-generated assets
- exclude SDP materializations
- do not show self-lineage unless there is a compelling reason
That is the kind of implementation detail that does not make it into vendor brochures, but it is exactly the kind of thing experts notice immediately.
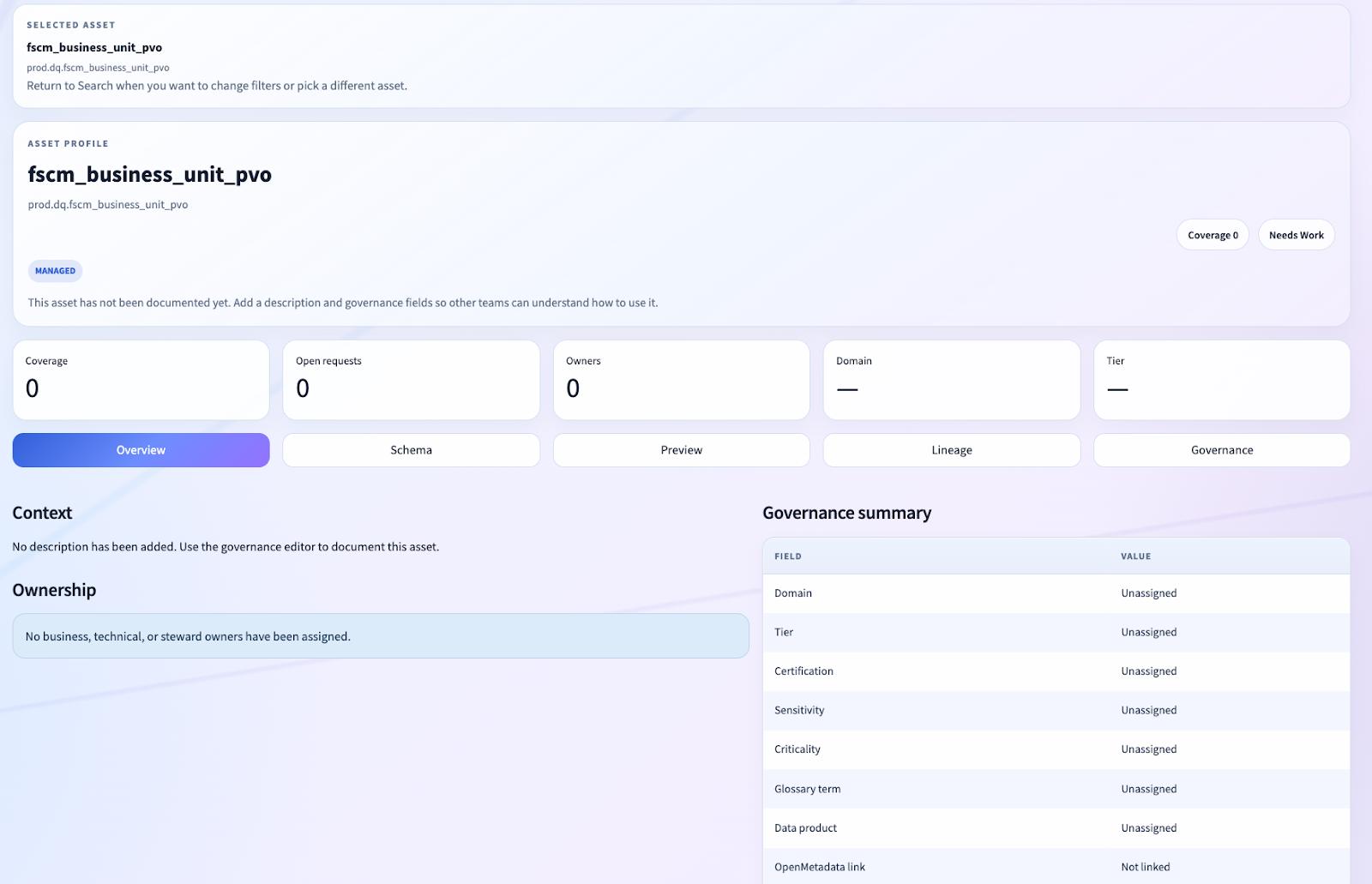
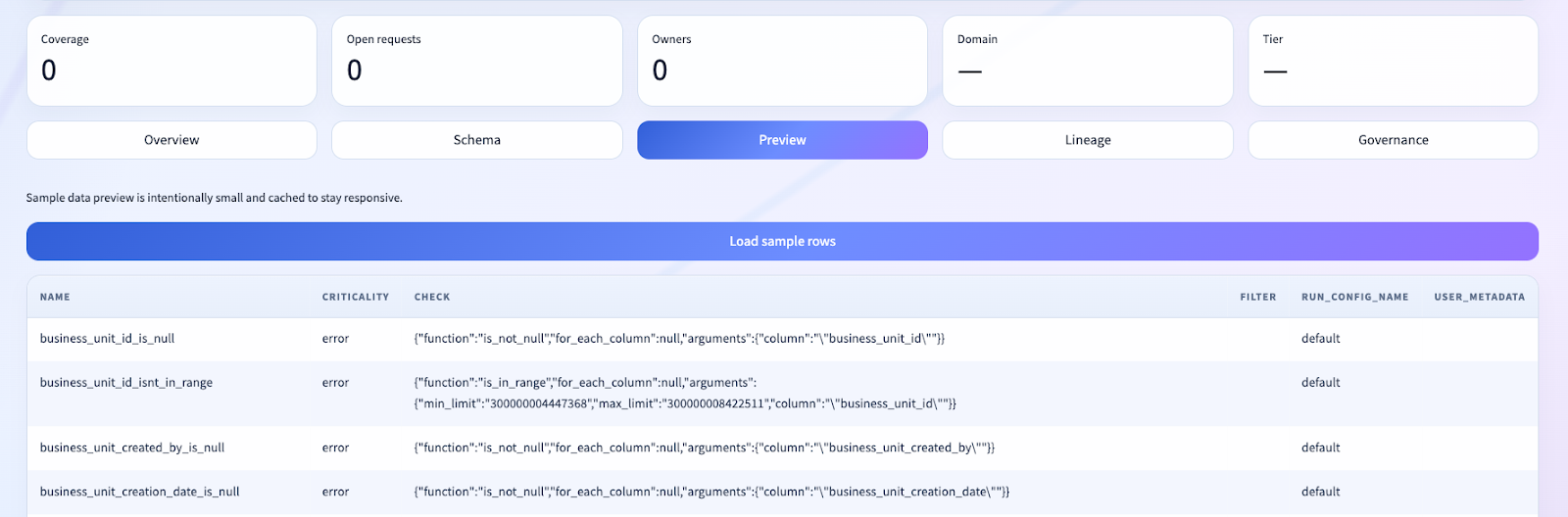
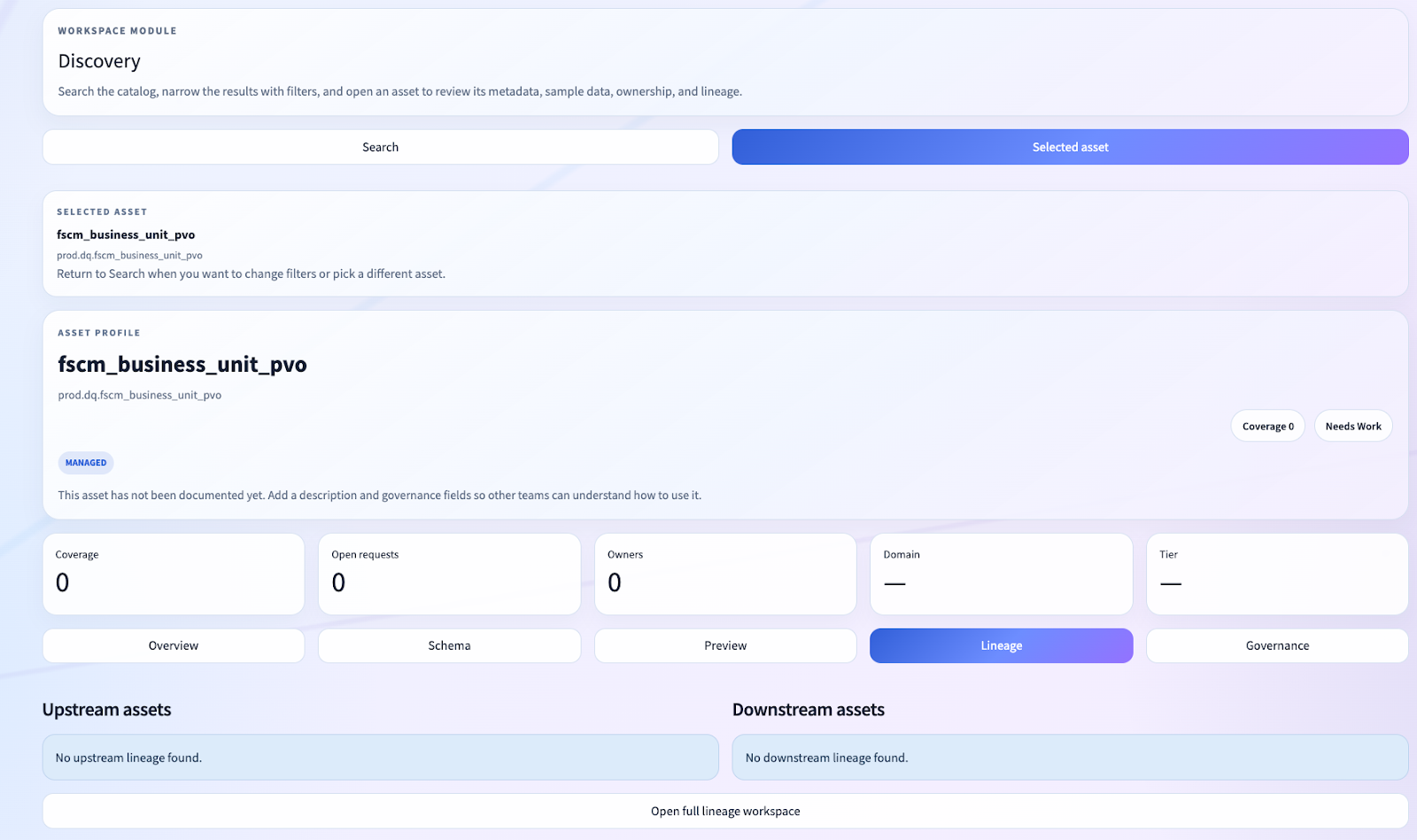
Asset Pages, Not Admin Screens
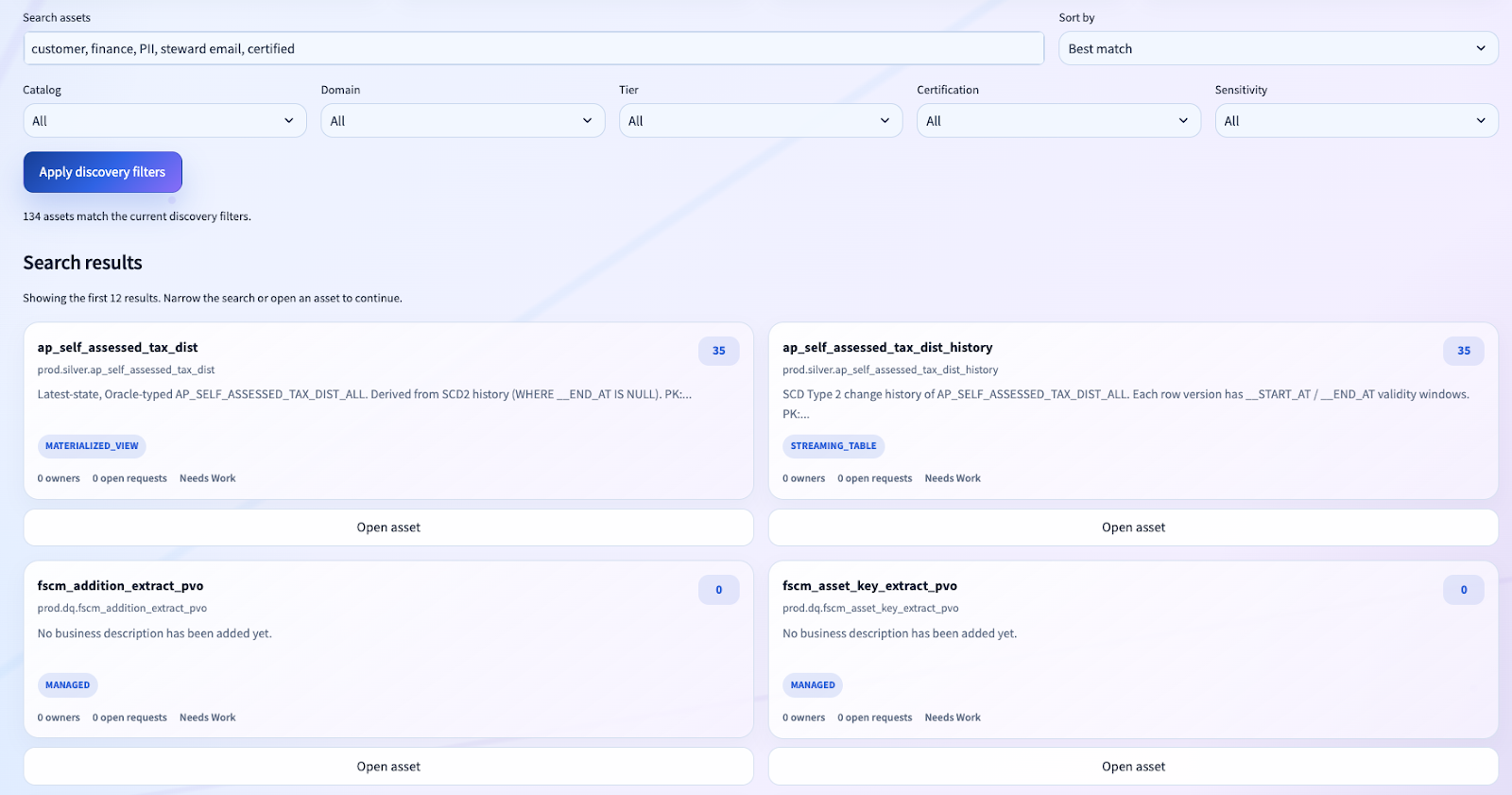
Another major design choice was to make the app asset-centric.
The user does not start from a loose collection of tools. They start from search, find an asset, and then work from an entity page.
The asset profile is a multi-surface governance workspace:
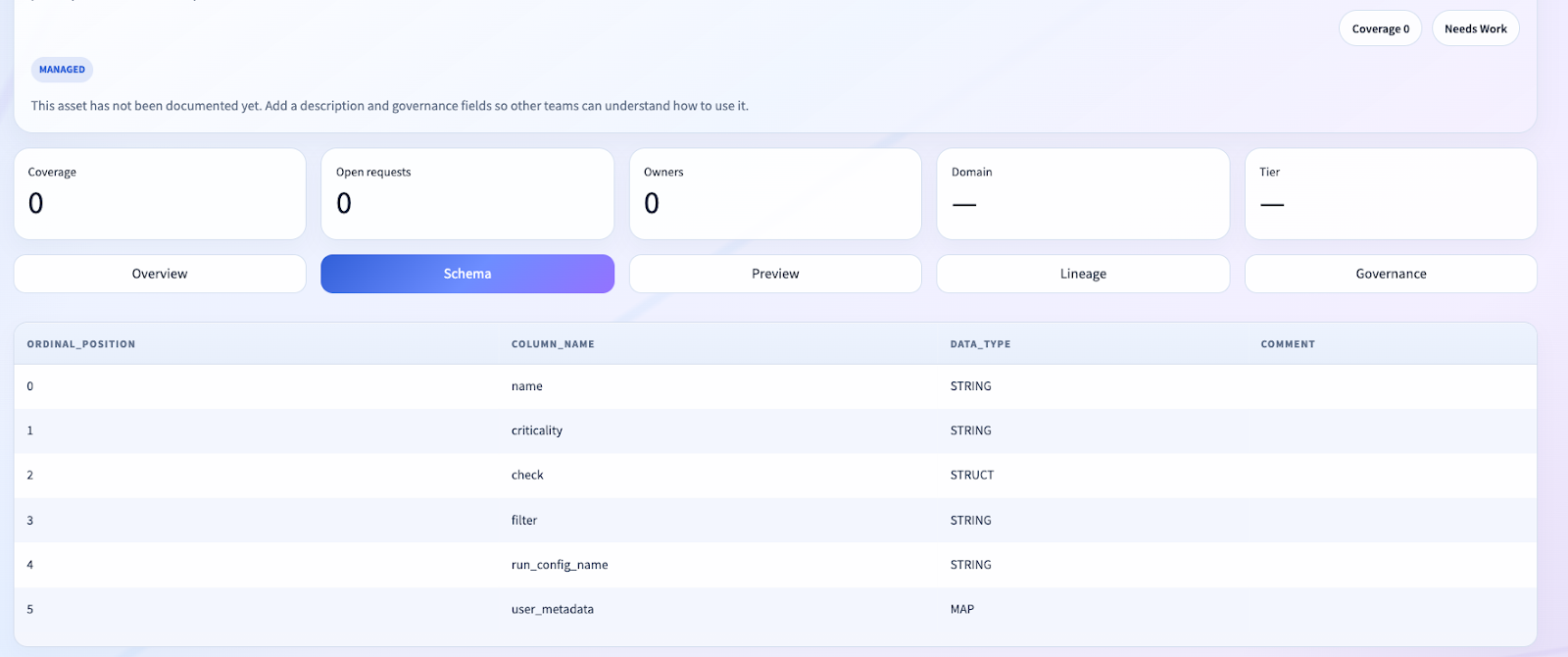
- Overview
- Schema
- Preview
- Lineage
- Governance
That one decision matters more than it may appear.
By structuring the experience as an entity page, we made it possible to unify:
- technical metadata
- stewardship actions
- governance fields
- sample data
- lineage
- change workflows
That is much closer to how OpenMetadata and DataHub succeed than the usual “custom app” pattern where every function becomes its own disconnected screen.
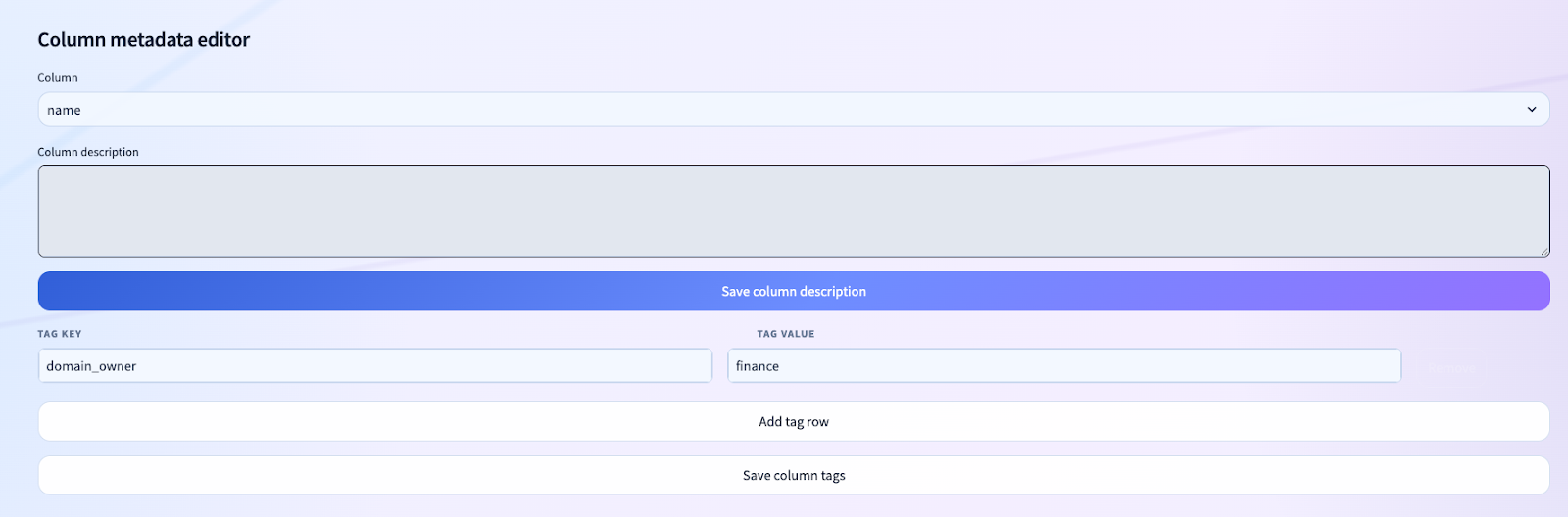
Native Metadata Mutation: Comments and Tags Flow Back Into Unity Catalog
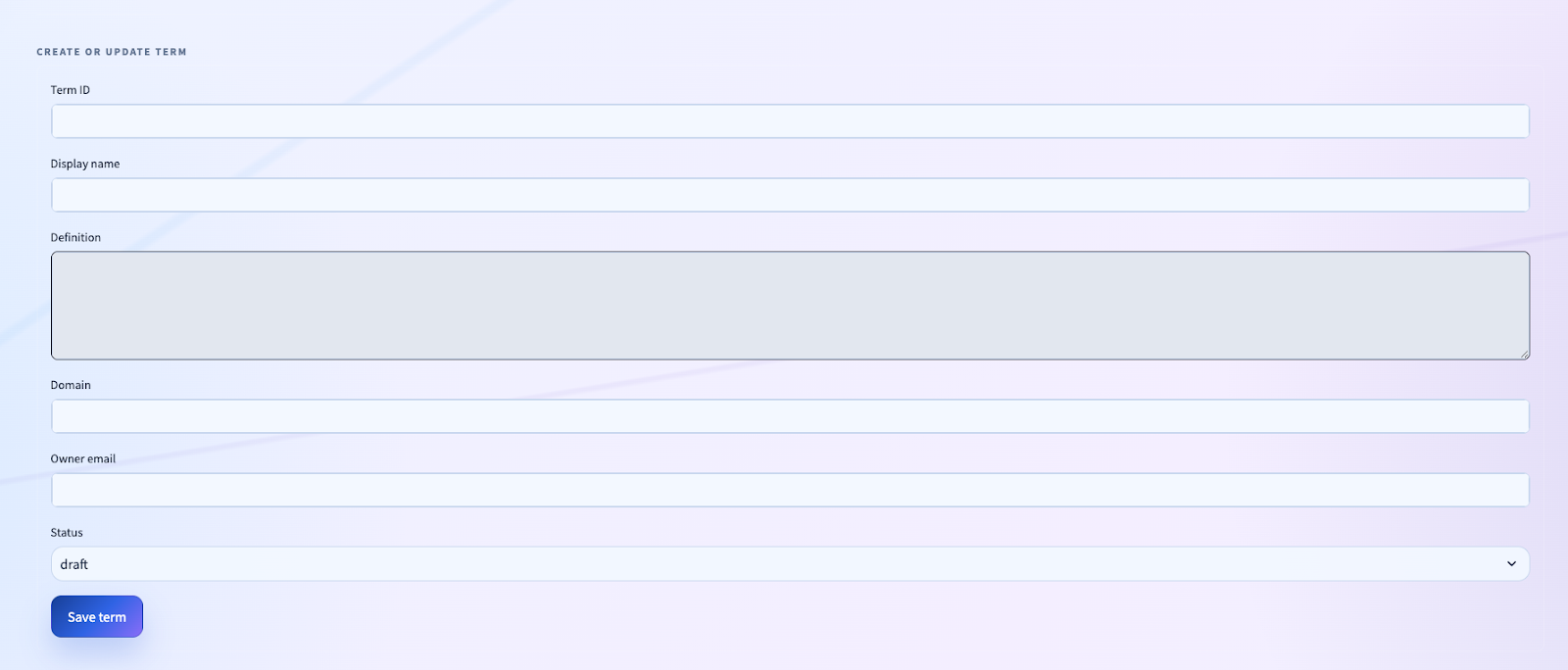
A governance product that only observes metadata is not enough. It has to be able to operationalize it.
That is why we implemented direct mutations into Unity Catalog for:
- table comments
- table tags
- column comments
- column tags
This is a fundamental architectural win.
We are not storing governance intent in a side database and hoping someone syncs it later. We are pushing the authoritative physical metadata changes directly into Unity Catalog.
That means:
- SQL users see the same descriptions the governance app manages
- comments and tags travel with the asset
- the governance surface and the technical surface stay aligned
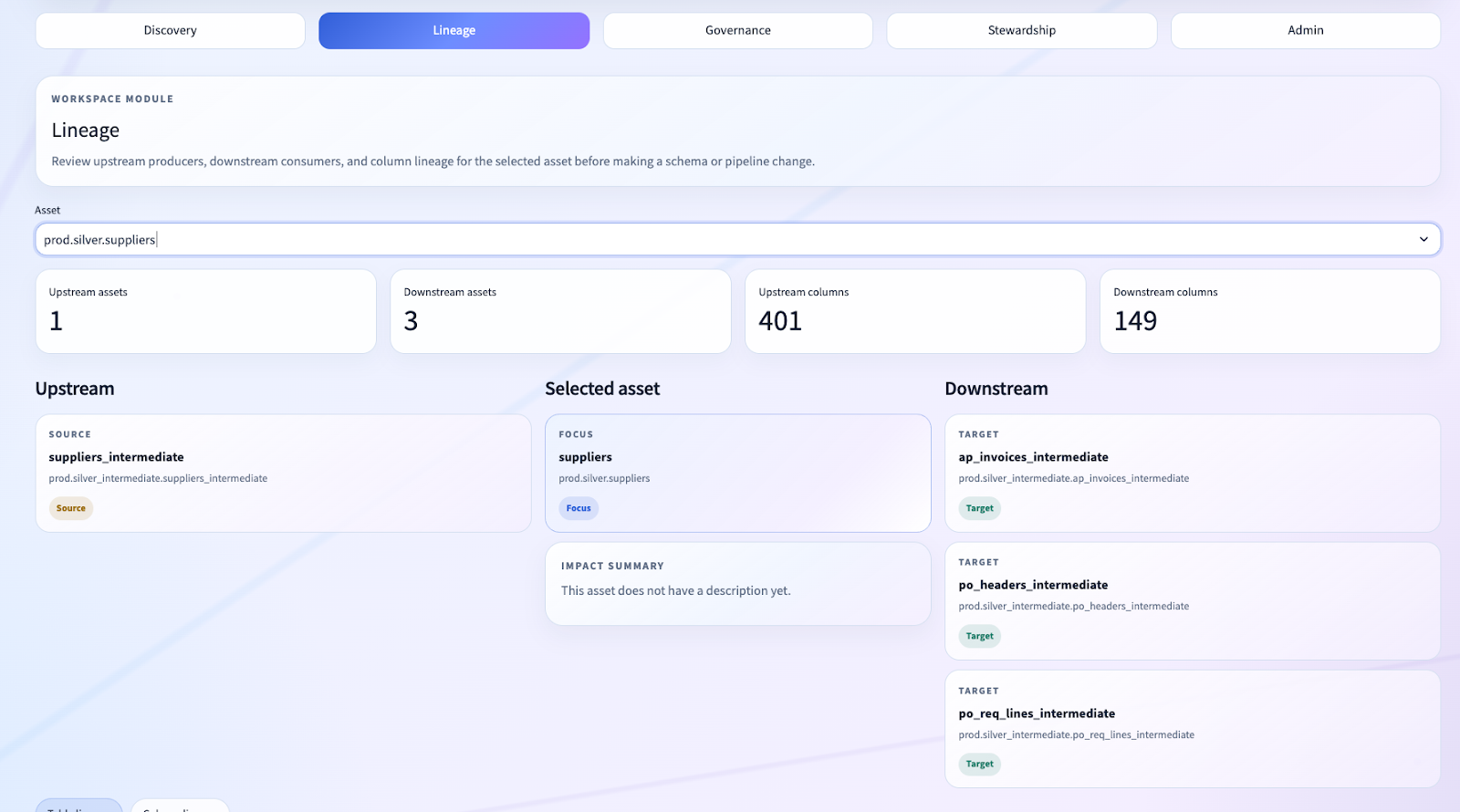
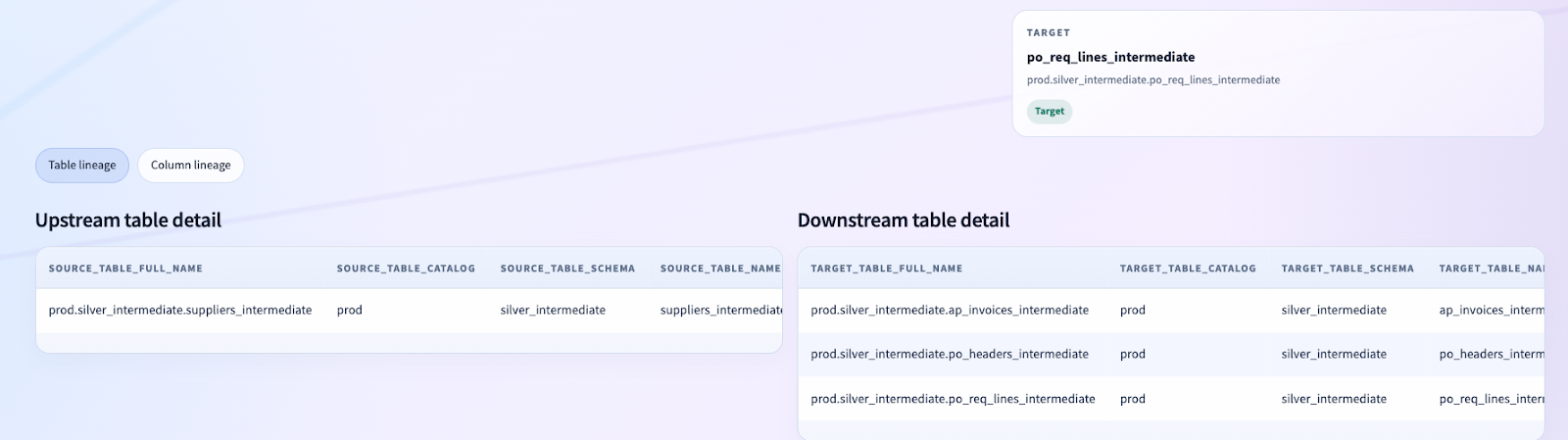
Column-Level Lineage Without External Infrastructure
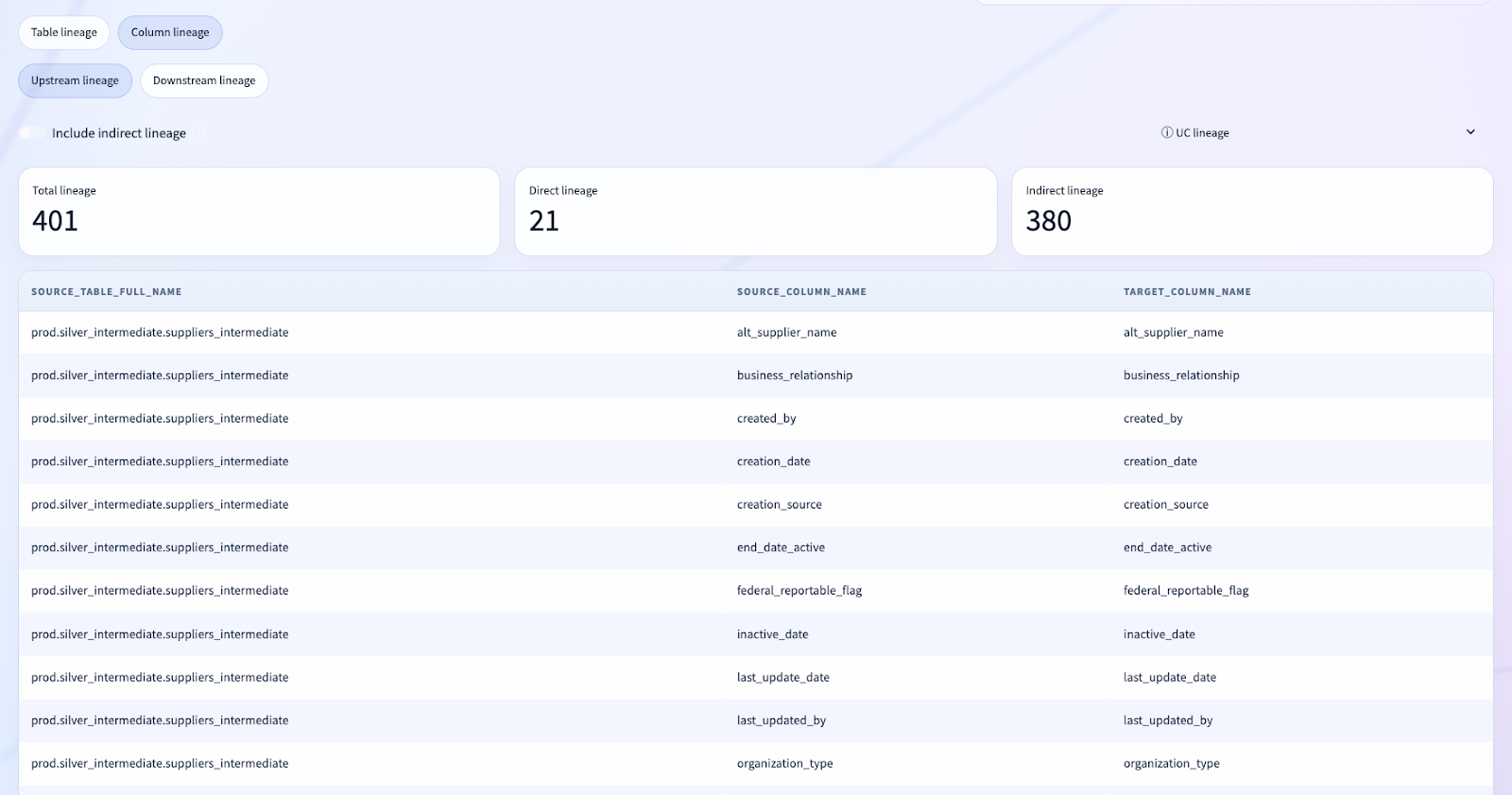
For many clients, column-level lineage is where governance tools either become compelling or become impossible to trust.
We intentionally built the lineage workspace on top of Databricks-native system tables rather than outsourcing the problem to a third-party graph store.
We present:
- upstream asset nodes
- selected asset focus
- downstream asset nodes
- table lineage detail
- column lineage detail
And critically, we filter out self-lineage and excluded noise before the user ever sees it.
This was one of the harder product-quality lessons from the implementation. Raw lineage is not product lineage. You have to shape it into something people can actually reason about.
Role-Aware Governance Workflows
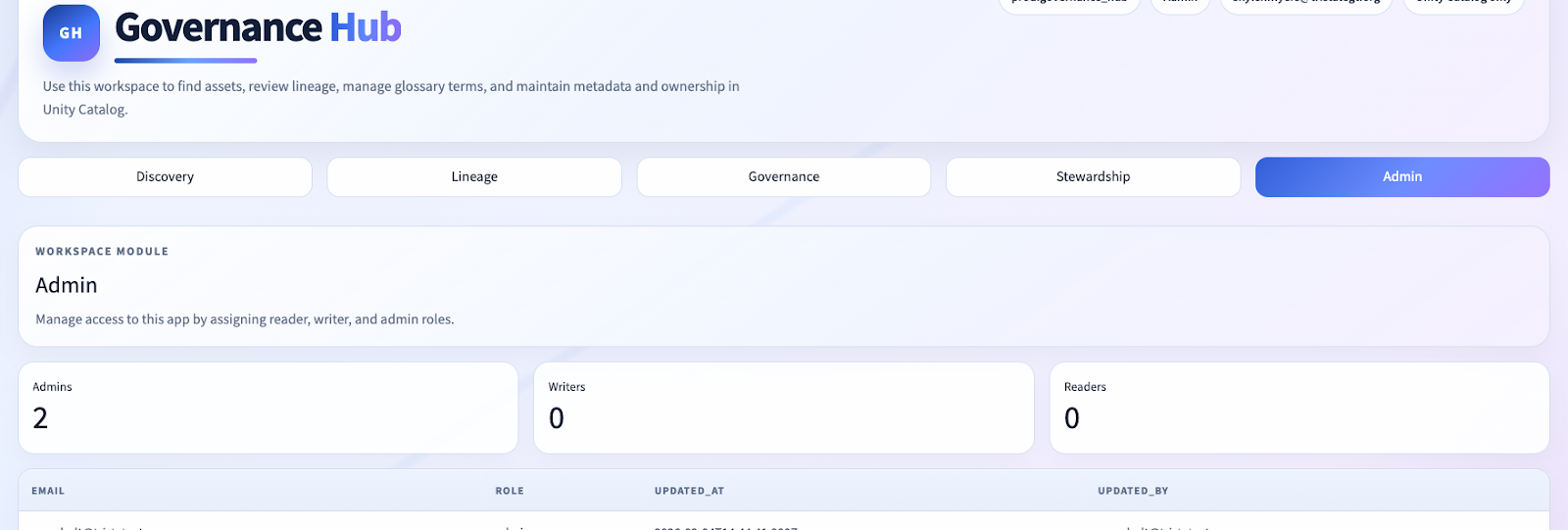
A governance app is not credible if every user can edit everything.
We introduced a simple but effective role model:
readerwriteradmin
These are stored in Delta and bootstrapped from configured admin emails. The app behavior changes based on role.
In practice, that means:
- writers/admins can directly edit metadata
- readers can participate without owning destructive privileges
- governance actions can be captured as proposed changes
This matters because the best governance products are not only catalogs; they are operational workflow surfaces.
That is why the repo includes a change_requests control-plane table and a ChangeRequest model.
That structure gives us a path from “metadata is wrong” to “metadata is corrected,” inside the same app surface.
Optional OpenMetadata Bridge Without Making It a Hard Dependency
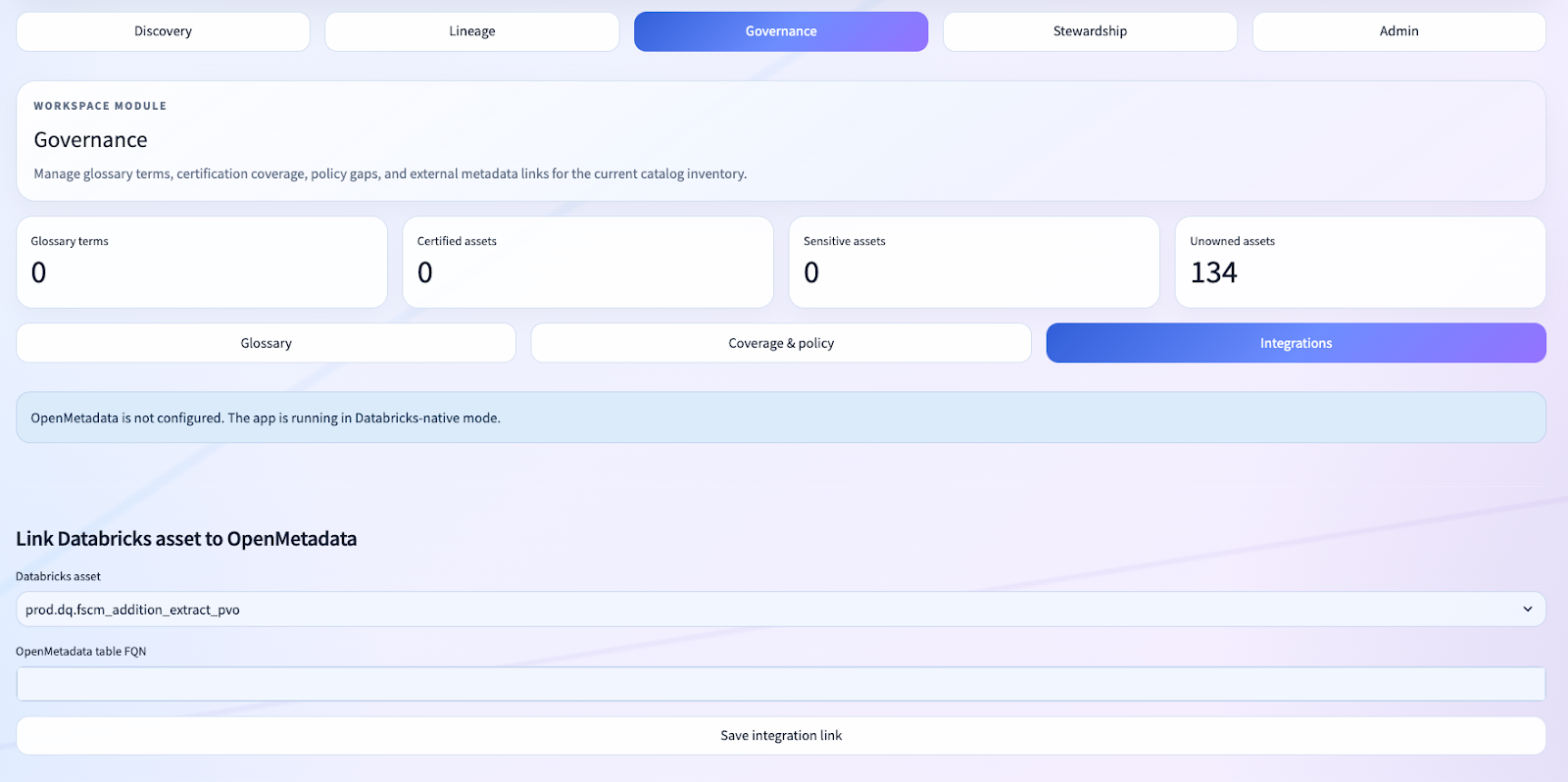
One of the more interesting aspects of this accelerator is that we did not force an all-or-nothing architecture.
For clients who are already invested in OpenMetadata or want to bridge into a wider metadata ecosystem, the app supports an optional OpenMetadata connector.
The client is intentionally thin.
And in the governance experience, we surface integration workflows rather than hard-coding the app around them.
That is an important architectural choice.
A lot of accelerators become less useful because they assume a single target-state architecture. We kept the accelerator Databricks-native first, but gave it enough extension points to participate in broader metadata programs.
Performance Hardening: The Work Behind the Work
The visible product is discovery, lineage, and governance.
But a large amount of the actual engineering effort in this repo went into hardening the app so that it behaves like a product rather than a Streamlit experiment.
Some of the notable implementation work included:
- cache design for metadata-heavy surfaces
- rerun-loop fixes in schema editing flows
- explicit state management for discovery search vs selected asset modes
- lighter-weight section loading to avoid pulling every expensive dataset at once
- load-state cleanup in the Databricks App shell
- consistent enterprise styling for BaseWeb/Streamlit controls
- background and layout experimentation, including reverting visual ideas that interfered with startup
That last point matters.
One of the easiest ways to spot an immature internal app is when visual polish is allowed to break runtime stability. In this project, we explicitly backed away from a full-screen animated overlay after it introduced startup regressions. That is exactly the kind of judgment production teams need to show.
Experts will appreciate that because it signals we were optimizing for the actual product, not a screenshot.
Why This Is an Entrada Accelerator, Not Just a Toy
We built Governance Hub so it can be installed in a client workspace quickly and then extended pragmatically.
That is a big difference from “we built one bespoke governance app once.”
The accelerator already includes:
- environment-aware DAB deployment
- Databricks App resource wiring
- governance-state table bootstrap
- SQL warehouse execution layer
- role model
- glossary
- owner management
- asset linking
- change requests
- discovery UX
- lineage UX
- optional OpenMetadata bridge
In other words, the difficult foundation work is already done.
That means Entrada can walk into a client environment and have a materially useful governance operating layer running much faster than a greenfield effort.
Then we tailor from there:
- client taxonomy
- policy model
- stewardship model
- domain-specific filters
- integrations
- approval workflows
- dashboards
That is the right pattern for enterprise governance work. Not “start from scratch every time,” and not “force every client into a rigid product box.”
The Business Value: What This Unlocks for Clients
The technical wins matter, but only because they lead to business wins.
Governance Hub creates value in a few very concrete ways.
1. It gives governance teams a real operating surface inside Databricks
Not a collection of notebooks. Not a spreadsheet-backed glossary. Not a SharePoint graveyard.
A real application.
2. It moves metadata stewardship closer to the assets
Comments, tags, owners, glossary references, and lineage context are managed where the data teams already work.
3. It reduces platform sprawl
Clients do not need to start with another heavyweight platform just to stand up a credible governance experience.
4. It gives data consumers something better than raw metadata screens
Search-first discovery and entity-centric pages dramatically improve usability for governance leads, stewards, analysts, and platform teams.
5. It is extensible in the language clients already use
Python, SQL, Delta, Unity Catalog, Databricks Apps, Databricks Asset Bundles.
That is a much better operating model than black-box governance software.
What We Think Databricks Experts Will Appreciate Most
If you are deeply familiar with Databricks, the strongest part of this implementation is not any single screen.
It is the combination of product and platform decisions:
- we used Databricks Apps as a serious application surface
- we used a SQL warehouse as the metadata/query plane
- we used Unity Catalog and system tables as the operational metadata backbone
- we used Delta tables as the governance control plane
- we preserved optionality with an OpenMetadata connector
- we shaped the user experience toward OpenMetadata/DataHub quality while staying native to Databricks
That is the kind of architecture that respects the grain of the platform instead of fighting it.
And that is why this matters beyond this one repo.
This project demonstrates that Databricks can support much richer governance products than many teams assume, provided you are willing to do the product design and systems engineering work properly.
Where We Would Push It Next
Because this is an accelerator, we are already thinking about the next layers:
- precomputed metadata snapshots to reduce cold-query latency
- richer policy and standards modules
- governance communications/update feeds
- Power BI and ServiceNow integration surfaces
- dashboard embeddings
- deeper glossary linkage and automated recommendation flows
- role-aware personalization
- more opinionated stewardship queues
But the important point is this: the foundation is already strong enough to install now and start delivering value immediately.
Closing
At Entrada, we did not build the Governance Hub to prove that a Databricks App can render a few metadata tables.
We built it to prove something much more interesting:
that Databricks can host a legitimate internal metadata product experience when the architecture is native, the workflows are asset-centric, and the governance state is treated as a first-class control plane.
That is the difference between an internal helper and an accelerator that clients can actually adopt.
If your organization wants the feel of OpenMetadata or DataHub, but wants it implemented in a Databricks-native way that lands directly in your own workspace, Governance Hub is exactly the kind of pattern we at Entrada are building for.
And because it is already packaged as a Databricks App accelerator, we can help clients move from concept to installable governance product far faster than the traditional catalog-tool playbook would suggest.


