 Data Engineering
Data Engineering  Data Strategy + Governance
Data Strategy + Governance  Data Migrations
Data Migrations  Concierge + Support
Concierge + Support  Artificial Intelligence
Artificial Intelligence  Training + Enablement
Training + Enablement  Data Analytics + Insights
Data Analytics + Insights  Financial Services
Financial Services  Communications, Media + Entertainment
Communications, Media + Entertainment  Healthcare + Life Sciences
Healthcare + Life Sciences  Technology + Digital Natives
Technology + Digital Natives  Manufacturing + Automotive
Manufacturing + Automotive  Public Sector
Public Sector  Retail + Consumer Goods
Retail + Consumer Goods  Race to the Lakehouse
Race to the Lakehouse  AI + Data Maturity Assessment
AI + Data Maturity Assessment  Unity Catalog
Unity Catalog  Rapid GenAI
Rapid GenAI  Modern Data Connectivity
Modern Data Connectivity  Gatehouse Security
Gatehouse Security  Health Check
Health Check  Sample Use Case Library
Sample Use Case Library  Blog
Blog  Events
Events  About Us
About Us  Careers
Careers  Founding Team
Founding Team 
Databricks model monitoring matters most after deployment, when machine learning systems start facing real-world conditions. When people talk about machine learning, they usually focus on getting a model built and deployed.
That makes sense. Training, tuning, validation, and launch are visible milestones. They are easy to rally around. But in real-world delivery, deployment is not the finish line. It is the point where the real work begins.
From my perspective, one of the clearest markers of AI maturity is whether a team knows how to monitor models once they are in production. Because a model can look great in development and still become unreliable once it starts operating in a live business environment.
Data changes. User behavior changes. Business conditions change. And when that happens, model quality can erode quietly.
That is why monitoring matters so much.
The Production Problem Teams Underestimate
A model rarely fails in a dramatic way.
More often, it degrades slowly:
- input distributions shift
- prediction quality starts slipping
- latency increases
- labels arrive late, making evaluation harder
- business users lose confidence in the outputs
And the dangerous part is that this can happen while everything still appears technically “live.”
A working endpoint is not the same thing as a reliable model.
That distinction matters, especially in enterprise environments where models influence decisions, automate workflows, or support customer-facing experiences. If no one is watching closely, the problem is not just technical debt. It becomes a business risk.
Why Monitoring Matters More Than Ever
Monitoring is often framed as a technical operations topic, but I think that view is too narrow.
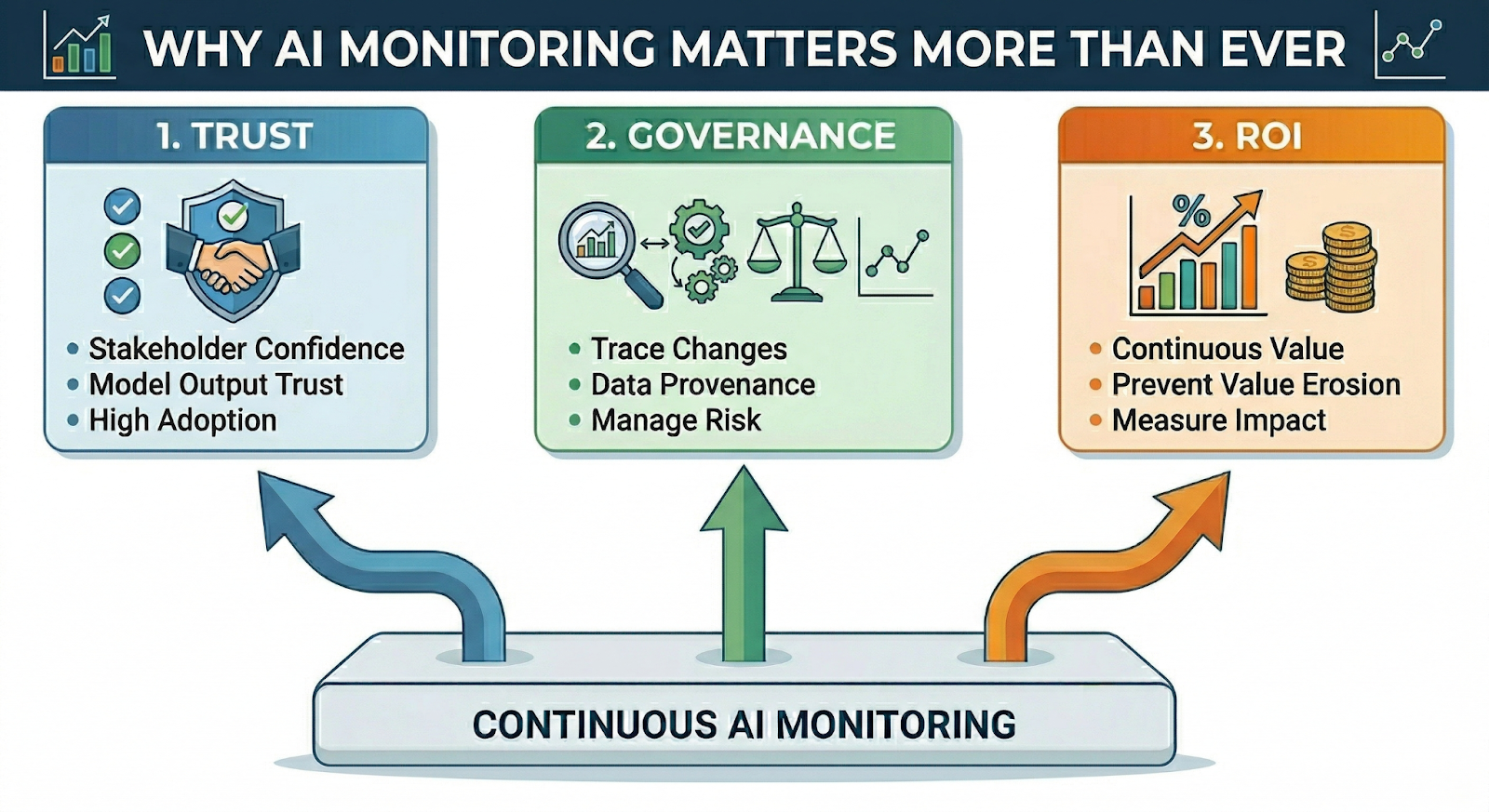
Good monitoring supports three things that matter to every serious AI program:
1. Trust
If stakeholders cannot trust model outputs, adoption drops quickly.
2. Governance
If you cannot trace what changed, what data was used, or how the model is behaving over time, you cannot manage risk properly.
3. ROI
If a model stops delivering value after launch, the return on the original investment starts to erode.
This is why monitoring should never be treated as phase two. It should be part of the production design from the start.
How I Think About This at Entrada
At Entrada, the way I approach this is shaped by the three pillars behind my role.
Platform Architecture
We focus on building resilient, high-performance data and AI platforms on the Lakehouse.
That includes production observability. Monitoring cannot depend on disconnected tools and manual checks. It has to be part of the architecture.
Governance and Quality
This is where I spend a lot of my attention.
AI systems need standards. Not just for performance, but for maintainability, explainability, quality, and responsible use over time. A model that works once is not enough. It needs to remain usable, governable, and credible after deployment.
Business Value Acceleration
Monitoring is one of the most practical ways to protect business value.
A model in production should not just exist; it should continue to create measurable outcomes. If performance drifts, if confidence drops, or if usage declines, teams need to know early and act quickly.
Where Databricks Fits In
One of the reasons Databricks is so effective in this area is that it helps teams approach monitoring as part of a connected platform, rather than as a patchwork of tools.
Several parts of the Databricks ecosystem are especially relevant here:
- MLflow for experiment tracking, model lifecycle management, and evaluation
- Mosaic AI Model Serving for production inference
- Inference tables for capturing request and response data from serving endpoints
- Unity Catalog for governance, lineage, and controlled access to data and AI assets
What I like about this model is that it makes production monitoring much more practical.
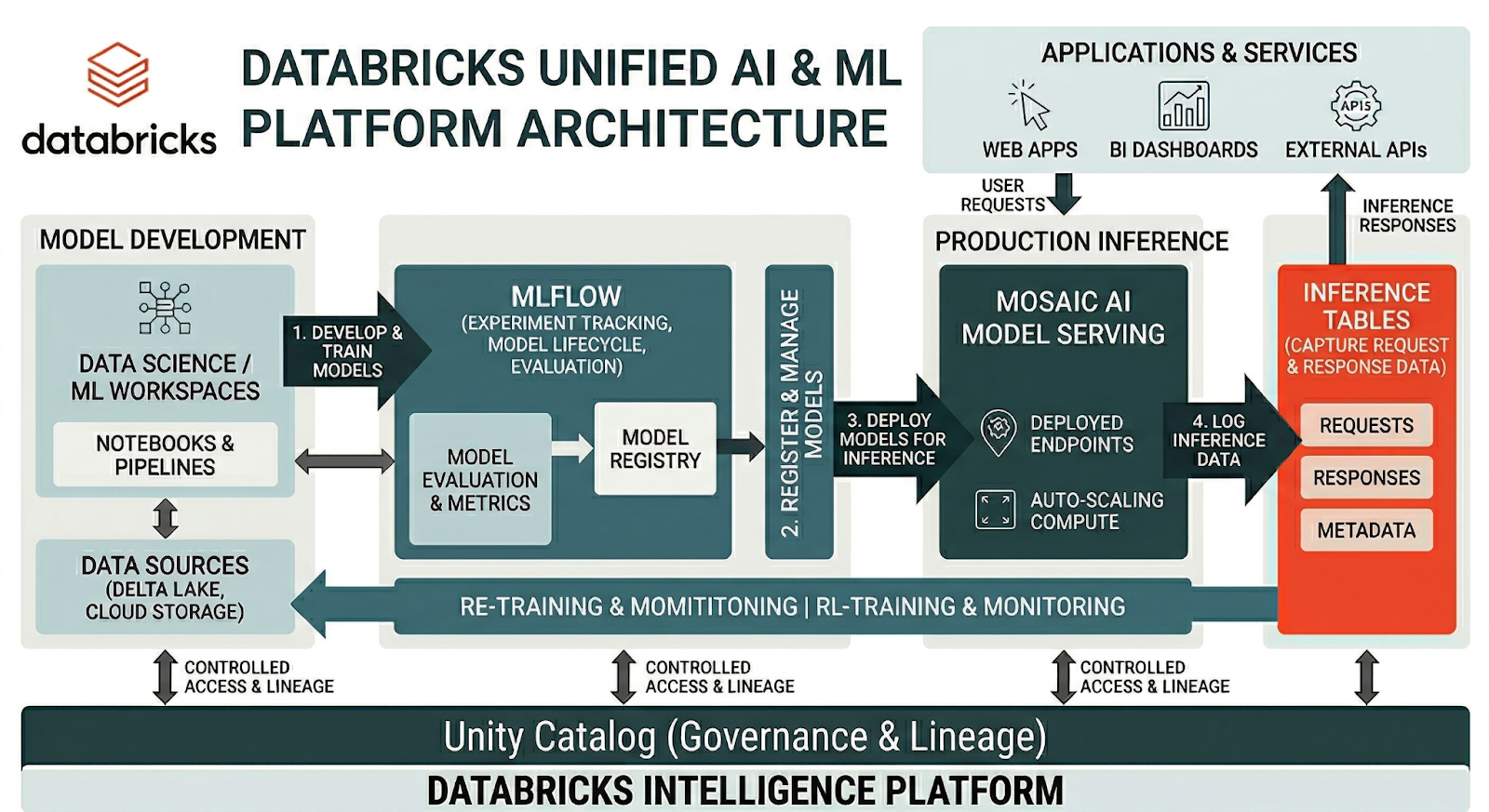
Instead of treating deployed models as a black box, teams can capture what is happening in production, analyze it over time, connect it to governed data assets, and create a much stronger feedback loop for improvement.
That is a much healthier operating model than relying on fragmented logging and reactive troubleshooting.
What Good Monitoring Actually Looks Like
In practice, strong model monitoring is not just one dashboard.
It usually includes a combination of signals such as:
- Prediction drift
- Data drift
- Latency and throughput
- Model quality over time
- Freshness of features or labels
- System behavior after deployment
- Downstream business impact
The exact mix depends on the use case, but the point is the same: teams need visibility into both technical performance and business relevance.
That is especially important because production issues do not always show up first as a broken system. Sometimes they show up first as weaker outcomes.
Monitoring Should Be Designed In, Not Added Later
This is one of the most common mistakes I see.
A team gets the model live first, then starts thinking about monitoring afterward. By that point, the logging is incomplete, governance is inconsistent, and it becomes harder to answer basic questions like:
- What changed?
- When did performance begin to shift?
- Which data inputs were involved?
- How does this affect the business outcome we care about?
The stronger approach is to build monitoring into the architecture from day one.
That means planning for:
- What needs to be logged
- What success looks like after launch
- What thresholds matter
- What should trigger review or action
- Who owns response when quality changes
This is where platform discipline pays off.
Why This Matters Even More for GenAI
This conversation is becoming even more important as teams move beyond traditional ML into GenAI and agent-based systems.
Now the question is not only whether a prediction is accurate.
It is also whether the system is:
- Grounded
- Consistent
- Reliable
- Aligned with user intent
That expands the monitoring challenge significantly.
It also makes governance more important, not less. As organizations push AI into more visible and business-critical workflows, the ability to observe and evaluate these systems over time becomes a requirement for scale.
A Few Practical Principles I Keep Coming Back To
Over time, I have found that the strongest production ML environments usually follow a few simple principles:
- Log more than you think you need: You will always want more historical context once something starts drifting.
- Monitor the system, not just the model: The endpoint may be live while the business value is quietly declining.
- Tie monitoring to outcomes: Technical metrics matter, but they are not enough on their own.
- Treat governance as part of monitoring: If you cannot explain what the model is doing or what changed, you do not really have control.
- Build for maintainability: The goal is not just to launch. It is to keep the system useful, trusted, and adaptable over time.
Final Thought
For me, AI maturity is not just about getting a model into production.
It is about building systems that can be observed, governed, improved, and trusted long after launch. That is why model monitoring matters so much. It protects quality, supports governance, and helps preserve business value when real-world conditions start to change.
And in enterprise AI, they always do.Ready to build AI systems that are observable, governable, and trusted long after launch? Contact Entrada to discuss how we protect your business value through production monitoring.


