 Data Engineering
Data Engineering  Data Strategy + Governance
Data Strategy + Governance  Data Migrations
Data Migrations  Concierge + Support
Concierge + Support  Artificial Intelligence
Artificial Intelligence  Training + Enablement
Training + Enablement  Data Analytics + Insights
Data Analytics + Insights  Financial Services
Financial Services  Communications, Media + Entertainment
Communications, Media + Entertainment  Healthcare + Life Sciences
Healthcare + Life Sciences  Technology + Digital Natives
Technology + Digital Natives  Manufacturing + Automotive
Manufacturing + Automotive  Public Sector
Public Sector  Retail + Consumer Goods
Retail + Consumer Goods  Race to the Lakehouse
Race to the Lakehouse  AI + Data Maturity Assessment
AI + Data Maturity Assessment  Unity Catalog
Unity Catalog  Rapid GenAI
Rapid GenAI  Modern Data Connectivity
Modern Data Connectivity  Gatehouse Security
Gatehouse Security  Health Check
Health Check  Sample Use Case Library
Sample Use Case Library  Blog
Blog  Events
Events  About Us
About Us  Careers
Careers  Founding Team
Founding Team 
Entrada agrees with that direction. But in production, the real optimization question is not “serverless or not?” It is “which parts of the DAG should be serverless, and which parts should not?” (Databricks Documentation)
That question matters even more now because serverless in 2026 is materially different from the earlier mental model many teams still carry. Serverless jobs automatically enable autoscaling and Photon. Jobs now expose Standard and Performance optimized modes, and Databricks says Standard mode can reduce costs by up to 70% for batch jobs and pipelines that can tolerate 4-6 minutes of startup (typically the startup time you’re used to seeing if you’re on classic compute). Dependency management has moved to serverless environments instead of init scripts, with cached packages reducing startup latency. And serverless is now paired with environment versions that provide a stable client API and a three year lifecycle; as of the current docs (April 2026), environment version 5 ships with Python 3.12.3 / Databricks Connect 18, while serverless version 18.0 is the current service release. (Databricks Documentation)
Just as importantly, serverless is not simply an old cluster without cluster creation. Databricks documents it as a Lakeguard isolated, Spark Connect based execution model that uses standard access mode. That is why successful serverless migrations are partly about compatibility, not just performance: Unity Catalog, standard-access-mode behavior, and modern runtime assumptions matter before anyone starts comparing runtimes or DBUs. (Databricks Documentation)
Entrada’s field lesson from some of our most complex clients
In one real Entrada engagement involving a massive graph publication and clustering pipeline, the whole evaluation pivoted on one enormous table. In the sampled run, that table alone accounted for 2.8B rows and 1.59 TB of reads, with 725 GB written in a single clone/write step. The next five named large tables in the same report sum to roughly 833 GB of reads. In other words, one table outweighed the next five combined by about 1.9x. That is the kind of workload shape that decides architecture before anyone debates cluster ideology.
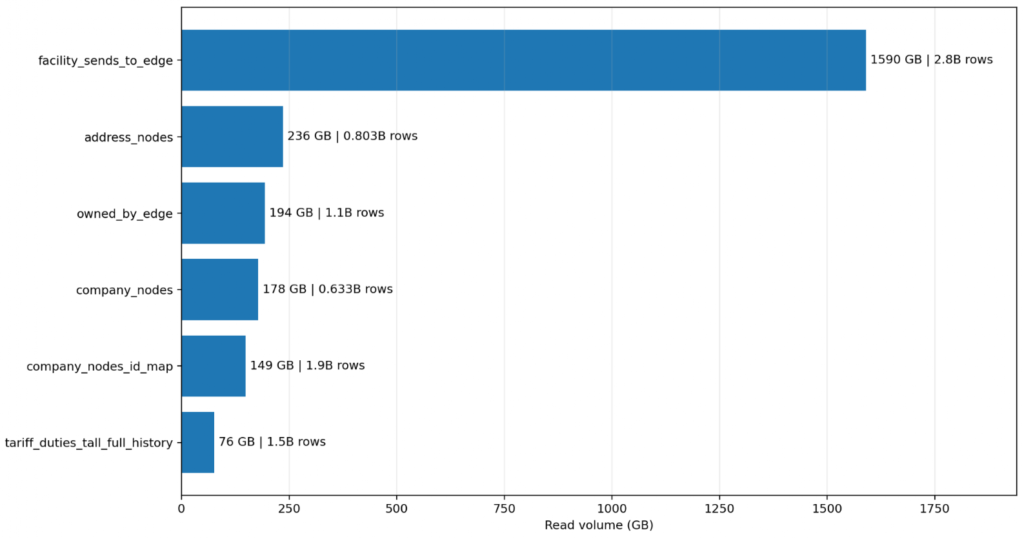
One table accounted for 1.59 TB of reads, outweighing the next five combined by 1.9x. This extreme shape indicates when a workload requires the larger memory envelope of Classic Photon.
On serverless, Entrada saw the classic failure mode for the wrong workload shape: the shuffle spill tax. One measured stage read 361.27 GB yet spilled 509.59 GB, a spill/read ratio above 1.4x. A later stage spilled 830.45 GB as the scale and data shape worsened. The critical Spark nuance is that memory pressure is paid per executor, not as a pooled cluster total. If the working set does not fit the executor envelope, it spills, and a bounded serverless tuning surface leaves fewer ways to compensate.
That does not make serverless a bad product. It makes it the wrong execution surface for a specific class of stages. In fact, Databricks’ own current guidance now makes essentially the same distinction: serverless is the recommended choice for most automated workloads, while classic jobs compute remains the answer for non-SQL jobs that require custom cluster settings not available in serverless. Entrada’s field conclusion matched that guidance almost exactly: serverless first for the broad middle, classic Photon where executor memory, skew management, and tuning still matter. (Databricks Documentation)
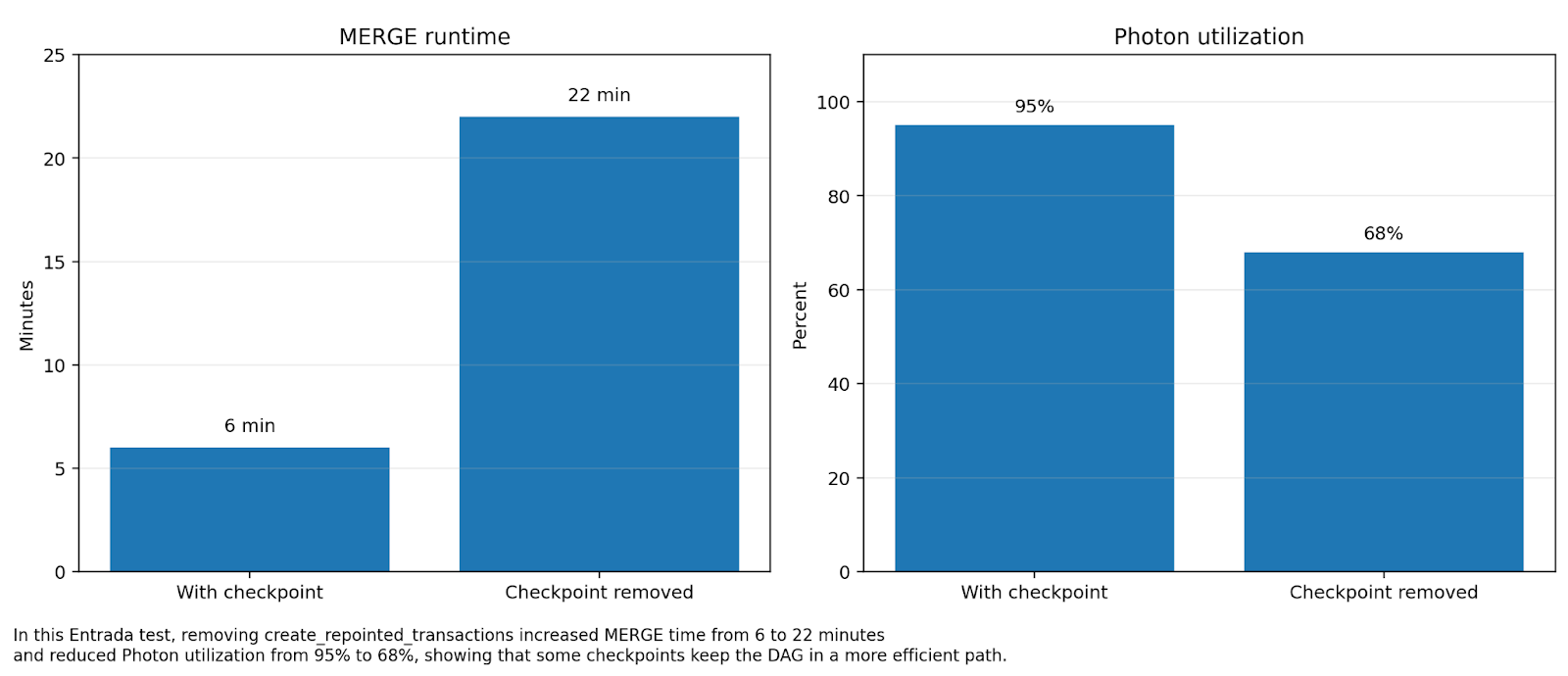
Removing a checkpoint increased MERGE runtime by 3.6x and dropped Photon utilization from 95% to 68%, proving that materialization is often a performance optimization rather than overhead.
Three metrics Entrada now uses in serverless design reviews
Most teams still classify workloads as “small,” “medium,” or “large,” which is not nearly predictive enough. Entrada has found three more useful design review metrics.
| Entrada review metric | Why it matters | Field signal |
| Dominant table ratio | Largest table read footprint vs the next major tables | The largest table was ~1.9x the next five large tables combined |
| Spill/read ratio | Distinguishes “big” from “mismatched” | One serverless stage spilled 509.59 GB on 361.27 GB read (>1.4x) |
| Photon coverage floor | Separates SQL native stages from Python heavy stages | Python/Pandas stages dropped to ~1% Photon time |
These are not official Databricks product metrics. They are Entrada field heuristics. But in practice they were more predictive than generic job size labels, because they point directly at the things that determine serverless price/performance: data shape, execution engine, and memory behavior.
The real novelty: optimize for serverless by preserving execution shape
Most serverless tuning articles focus on levers inside serverless. That is useful but incomplete. The deeper lever is execution shape: keep work on Photon native SQL and DataFrame surfaces, minimize multi-hundred-GB spill, decide checkpointing based on DAG simplification rather than purity, and route the few pathological stages to classic before they burn cost in DBUs and runtime variance. This is the real shift in serverless optimization: because the knob surface is intentionally smaller, architecture matters more and cluster tweaking matters less. Photon accelerates joins, aggregations, repeated cached reads, and Delta writes, and it runs by default on SQL warehouses and serverless notebooks/workflows, but UDFs and RDD APIs sit outside that envelope. (Databricks Documentation)
In the above referenced case, applyInPandas and similar Python paths collapsed Photon coverage to around 1% in the stages that used them. That matters because Databricks continues to improve the service. For example, serverless 18.0 (env version 5) introduced shared isolation execution environments for same owner Unity Catalog Python UDFs to improve performance and reduce memory usage, but that is not the same as making Python heavy stages Photon native. Treat Python heavy stages as a separate workload class, not as a footnote under “serverless will probably be faster.” (Databricks Documentation)
The checkpoint paradox: sometimes the extra write is the optimization
This was one of the most important non-obvious lessons from the engagement. A lot of performance guidance treats intermediate checkpoints or materialization as obvious overhead. Sometimes that is true. Sometimes it is exactly backwards. Entrada observed a case where removing a materialized checkpoint made a MERGE dramatically slower: runtime increased from 6 minutes to 22 minutes, and Photon utilization dropped from 95% to 68%. For experts, that is the tell. Intermediate materialization is not simply “overhead vs elegance”; it is an execution shape decision that can either preserve or destroy the efficient path.
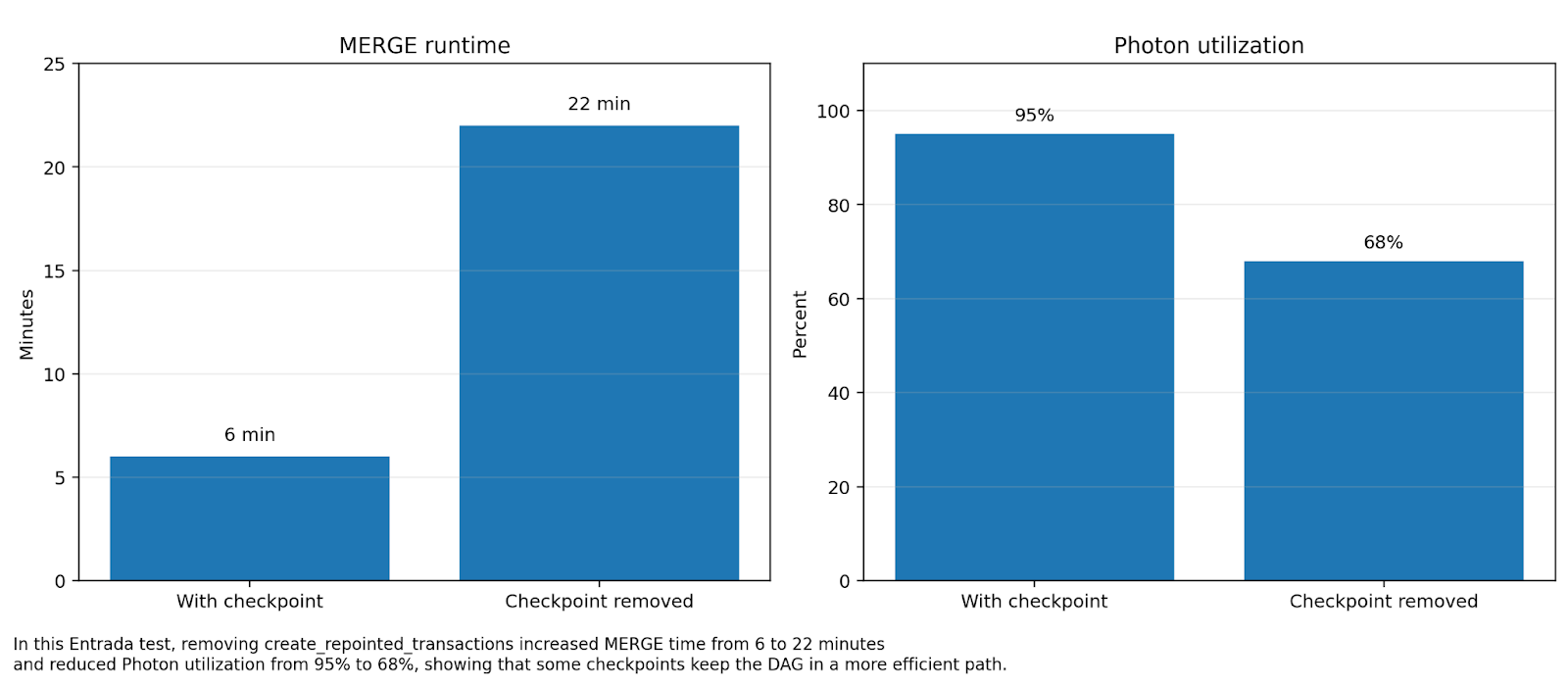
Entrada results show that removing intermediate materialization increased runtime by 266%. Checkpoints are vital architectural tools for preserving the most efficient execution path on Databricks
Entrada also found that serverless cache is real but conditional. A later re-read of that aforementioned largest table showed 56.42 GB of cache hits, about a 16% hit rate, while a checkpoint table read showed only partial benefit at roughly 22%. So the right mental model is not “serverless cache will save us” or “checkpoints are always bad.” The right model is: cache helps when you re-read the same underlying Delta surface; rematerialization hurts when you keep forcing the system back into colder I/O paths.
Price/performance is now a routing problem, not a marketing slogan
Price/performance should be discussed with the same discipline. In this engagement, a classic run measured $119.27 in DBUs before separate cloud VM charges, and even after Entrada conceptually added the missing infrastructure cost, serverless still remained multiple-x more expensive for the heaviest long running path. It would be wrong to manufacture a precise ratio the case study does not publish. The useful lesson is narrower and more defensible: “serverless is cheaper” is not a safe assumption once a workload spends its life in wide shuffles, spill, and non-Photon execution.
That is why the best current Databricks guidance and the best field guidance are not actually in conflict. Databricks is right at the portfolio level: serverless should be the default for the broad middle of modern workloads. Entrada’s case study adds the operational precision: a small subset of stages can dominate cost and runtime so completely that forcing them onto serverless makes the overall estate worse, not better. (Databricks Documentation)
The best setups on Databricks right now
Here is the setup pattern Entrada would recommend to most technical teams today.
| Workload class | Best setup | Why |
| SQL first models, BI, dbt SQL | Serverless SQL warehouse | Fastest startup, strong concurrency behavior, SQL first performance surface |
| Scheduled controller notebooks, Python wheels, dbt CLI, moderate transforms | Serverless Jobs using Standard mode | Lower DBU consumption when startup latency is not business critical |
| Latency sensitive operational tasks | Serverless Jobs using Performance optimized mode | Faster start and faster run path for time sensitive work |
| Billion row joins, skewed graph stages, multi-hundred-GB spill, Python heavy critical paths | Classic Photon memory optimized job clusters | Larger executor memory envelope, wider Spark tuning surface, better predictability |
The Databricks setup recommendations in that table come directly from current compute selection and SQL warehouse guidance; the “red flag” workload classes come from Entrada’s measured case study results. (Databricks Documentation)
1) SQ -first models, BI, and dbt SQL should default to Serverless SQL warehouses
Databricks says serverless SQL warehouses are recommended for BI, ETL, and exploratory analysis, typically start in 2-6 seconds, and scale rapidly with Intelligent Workload Management. For SQL first estates, that is one of the cleanest serverless wins on the platform. If you need custom networking or hybrid federation patterns in your own cloud network, that is the point where pro warehouses become more relevant. (Databricks Documentation)
2) Scheduled control plane tasks should default to Serverless Jobs in Standard mode
For scheduled orchestration, notebook tasks, Python wheels, and moderate DataFrame workloads, Serverless Jobs in Standard mode are often the best current price/performance choice. Databricks says serverless jobs are the recommended compute for notebooks, Python scripts, wheels, and dbt CLI tasks, and it explicitly positions Standard mode for batch jobs and pipelines that can tolerate 4-6 minutes of startup while lowering DBU usage. Many teams still pay Performance optimized DBUs for nightly or hourly work that does not need them. That is now an easily avoidable mistake. (Databricks Documentation)
Databricks also notes that jobs requiring large amounts of memory or many tasks can see increased startup times on serverless. That is another reason not to confuse orchestration friendly serverless with a universal substitute for every heavy Spark stage. (Databricks Documentation)
3) Preflight serverless migrations with compatibility, not optimism
Databricks’ current best practices page says the easiest workloads to migrate are those stored in Unity Catalog, compatible with standard access mode, and compatible with Databricks Runtime 14.3 or above. That guidance matters because serverless is a Lakeguard isolated, Spark Connect based environment, not simply an old all-purpose cluster with fewer buttons. In practice, Entrada recommends proving a workload on classic standard access mode first, then moving it to serverless. That catches a surprising number of “serverless issues” before they become expensive production surprises. (Databricks Documentation)
4) Manage dependencies the serverless way
Databricks explicitly says serverless does not support init scripts; libraries should be managed through serverless environments, whose packages are cached for subsequent runs. We found, for jobs that had high degrees of parallel task runs on the same serverless environment that had to install heavy Python packages, to bootstrap the environment with one quick task (just print something) which made subsequent tasks use that bootstrapped pre-configured environment instead of indenpendtly installing them all in the parallel tasks. Also validate the hard limitations up front: no R, no RDD APIs, no Maven coordinates, no global temp views, limited DBFS access, and custom data sources only through Lakehouse Federation. Teams that treat these as late cycle surprises are doing migration in the wrong order. (Databricks Documentation)
5) Use the bounded Spark configs that exist, but do not pretend they are a full tuning surface
Current serverless notebooks and jobs expose only a limited set of Spark properties, including spark.sql.shuffle.partitions (default auto), spark.sql.files.maxPartitionBytes, session timezone, ANSI mode, and execution timeout. Those are useful. They are not a substitute for the wider executor sizing and cluster tuning surface of classic jobs compute. The design consequence is simple: if a stage only becomes viable after deep tuning, it is telling you where it belongs. (Databricks Documentation)
Databricks is expanding serverless capabilities here too. In 18.0, the release notes show support for dynamic shuffle partition adjustment plus AQE and auto optimized shuffle in stateless streaming queries. That is meaningful progress. It still does not eliminate the basic field distinction between bounded control and fully tuneable compute. (Databricks Documentation)
6) Keep the high memory notebook feature in context
Databricks’ high memory serverless option raises notebook REPL memory from 16 GB to 32 GB and carries a higher DBU emission rate, but Databricks is explicit that it does not increase Spark session memory. It is useful for notebook side memory pressure. It is not the fix for shuffle-heavy billion-row joins. Entrada’s case study is exactly the kind of workload where that distinction matters. (Databricks Documentation)
7) For structured streaming on serverless, design micro batches on purpose
Databricks currently supports Trigger.AvailableNow but not time based trigger intervals on serverless, and it recommends maxFilesPerTrigger or maxBytesPerTrigger to keep micro batch size predictable. That is a real operational consideration, not a footnote, because unmanaged micro batches can turn a nominal streaming job into a spill heavy batch event. (Databricks Documentation)
8) Close the loop with FinOps and observability
Databricks documents system.billing.usage as the system table for monitoring serverless costs, including workload metadata such as job_run_id, job_name, notebook_path, and inherited custom_tags from serverless budget policies. For teams serious about price/performance, that means routing decisions can be audited rather than argued. Entrada recommends tagging by workload class and watching for patterns such as spill heavy stages that stay expensive despite modest code change. Because Spark UI is not available on serverless, query profiles should be treated as a first class debugging surface. (Databricks Documentation)
9) Security objections to serverless are weaker than they used to be
One historical objection to serverless was outbound network control. Databricks now documents serverless egress control, including deny-by-default outbound policies at Enterprise tier. For regulated or security sensitive shops, that materially changes the conversation from “we cannot put this on serverless” to “we can, if we define the network posture correctly.” (Databricks Documentation)
Where serverless won in Entrada’s case study and where it did not
Serverless was not the villain in this engagement. It was the right answer for SQL models, smaller transformations, orchestration, dev/test, interactive work, and the dbt orchestration layer running on a SQL warehouse. It gave exactly what serverless is supposed to give: elasticity, low cluster management overhead, and fast operational simplicity. For the parts of the DAG that were SQL heavy and bounded in shuffle behavior, serverless was a very good fit.
Classic Photon job clusters were the better answer for the stages that touched the massive, billion-row table at true scale, for graph clustering and repointing logic, for tasks that created multi-hundred-GB spill, and for Python heavy paths where Photon coverage was structurally limited. That is why Entrada recommended a hybrid architecture for this specific niche, ultra-memory intensive workload: not because serverless failed, but because the workload was heterogeneous and the heaviest stages had different physics than the controller layer around them.
Entrada’s recommended hybrid pattern
For these sorts of massive memory-scaled workloads, Entrada’s recommended architecture was a serverless first control plane plus classic Photon with memory-optimized compute for the heavy graph stages. Lightweight controller tasks run on serverless. A workload shape router classifies tasks by Photon surface area, expected spill, Python share, cache reuse vs rematerialization, and tuning/SLO requirements. SQL first models and smaller transforms stay on serverless. Python models touching ultra-wide, billion-row scale, graph clustering/repointing stages, and multi-hundred-GB spill stages route to memory optimized classic. Guardrails keep the boundary honest over time: if a model reads more than roughly 500 GB or 1B rows and performs joins/aggregations, it becomes a classic candidate; if stage spill exceeds roughly 100 GB, it becomes a classic or rewrite candidate.
That pattern is not anti-Databricks guidance. It is a more operationally precise implementation of it. Databricks recommends serverless for most automated workloads and classic jobs compute when custom cluster settings are required. Entrada’s contribution is to define the workload signals that tell you, early, which side of that line a task belongs on. (Databricks Documentation)
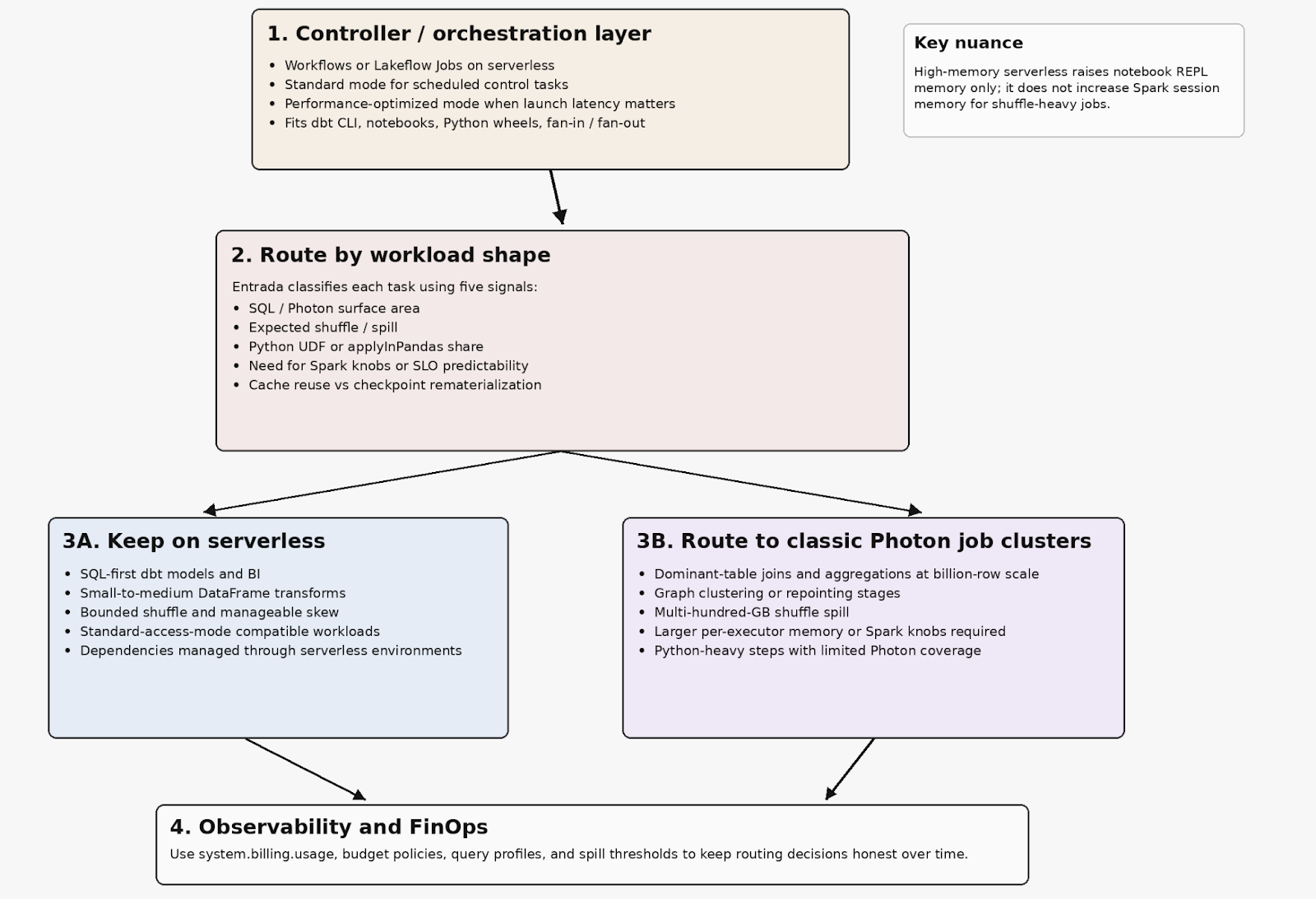
A serverless-first control plane combined with strategic routing for heavy stages ensures each task runs on the execution surface that provides the highest price/performance ROI.
Final takeaway
The future on Databricks is absolutely more serverless, not less. But the winning architecture is not “serverless everywhere.” It is “serverless where serverless has structural advantage.” That means using Standard mode aggressively for scheduled batch serverless work, keeping SQL first workloads on serverless SQL warehouses, preserving Photon friendly execution paths, and treating spill, Python share, rematerialization, and executor memory pressure as first class design signals. It also means using classic Photon job clusters unapologetically where the workload still needs them. (Databricks Documentation)
That is the central lesson Entrada would offer to any technical team optimizing Databricks for serverless in 2026: be serverless first, but route by workload shape. Hybrid is not indecision. Hybrid is what happens when a team is honest about execution physics.
To apply these insights and determine the optimal hybrid architecture for your specific data workloads, contact Entrada today to discuss a Databricks design review.


