 Data Engineering
Data Engineering  Data Strategy + Governance
Data Strategy + Governance  Data Migrations
Data Migrations  Concierge + Support
Concierge + Support  Artificial Intelligence
Artificial Intelligence  Training + Enablement
Training + Enablement  Data Analytics + Insights
Data Analytics + Insights  Financial Services
Financial Services  Communications, Media + Entertainment
Communications, Media + Entertainment  Healthcare + Life Sciences
Healthcare + Life Sciences  Technology + Digital Natives
Technology + Digital Natives  Manufacturing + Automotive
Manufacturing + Automotive  Public Sector
Public Sector  Retail + Consumer Goods
Retail + Consumer Goods  Race to the Lakehouse
Race to the Lakehouse  AI + Data Maturity Assessment
AI + Data Maturity Assessment  Unity Catalog
Unity Catalog  Rapid GenAI
Rapid GenAI  Modern Data Connectivity
Modern Data Connectivity  Gatehouse Security
Gatehouse Security  Health Check
Health Check  Sample Use Case Library
Sample Use Case Library  Blog
Blog  Events
Events  About Us
About Us  Careers
Careers  Founding Team
Founding Team 
Part II of Databricks vs Microsoft Fabric, A Multi-Part Blog Exploration of the Platforms and their Benefits
Introduction to Microsoft Fabric
Microsoft Fabric should be thought of less as a new technology and more of a collection of legacy tools designed to simplify the use of the Azure ecosystem. For example, Azure already provided services for different fields of data analytics, such as Power BI for business visualization, Azure Synapse Analytics for cloud data warehousing, and other tools/concepts like Spark notebooks, ADF-style task orchestration, ADLS cloud storage, the lakehouse, etc. Fabric is not a replacement of these systems – it is a bundling.
Power BI + Fabric Background
Microsoft Excel was one of the original computing tools that allowed some early form of data analysis abilities in the 80s and is often considered the first form of a nascent Power BI. These analysis abilities were incrementally improved with the release of pivot tables in the 90s and further enhanced in 2000 when Microsoft began to launch other stand-alone data analysis and modeling tools like SSAS. Around the same time, Microsoft had a secretive Project Gemini it was developing on the side that eventually came to be Power Pivot, which itself ushered in a wave of data exploration themed Excel add-ons in the early 2010s. Finally, in 2015 Power BI itself was released as a standalone product on its own website. It has now grown to be the business visualization market share leader for many years over, and only continues to trend upward.
Using Power BI
One of the major marketing points from Microsoft about Fabric is its native Power BI integration and specifically its Direct Lake mode. Traditionally, in order to visualize data in Power BI, there were three options:
- Import Mode: The most straightforward and commonly used approach. The data is imported into Power BI’s in-memory engine called VertiPaq, taking advantage of caching algorithms for faster querying capabilities. The data storage is optimized using compression mechanisms. This mode offers the quickest query performance but comes at the cost of having to refresh your stale data (since it is a snapshot of the last refresh). Since the data is replicated in PBI, this comes with governance and cost implications and the size is constrained by PBI’s available memory.
- DirectQuery Mode: Data remains in the source and is queried live by a source system endpoint. Data does not have to be refreshed, but performance can be slower given that the queries must be converted to the type that PBI generates. Network latency is also a factor since the data is not stored locally.
- Composite Models: This allows you to leverage both Import and DirectQuery modes within the same PBI model. Composite models are very flexible, allowing the import of smaller, frequently used datasets that benefit from the performance benefits while leaving larger, less used datasets on the server.
Direct Lake markets to bridge the gap between import and DQ modes by offering near real-time data access without duplicating storage on PBI due to its tight integration with OneLake. We will go into more detail about OneLake in a future blog about platform openness, but for now let’s dive deeper into these claims.
Integrating Power BI
The High Cost of Using Direct Lake
Despite it being advertised as removing the barriers of previous methods, Direct Lake comes with its own costs. In order to use Direct Lake with Power BI, the data must be stored in OneLake. However, the data that is stored in OneLake cannot be accessed without using Fabric Capacity Units.
For example, an organization which uses both Databricks + Fabric and wants to use Direct Lake must write their data to OneLake instead of an open cloud storage. This means that in order to read that data back with Databricks (or any other platform), they will have to consume both Capacity Units and DBUs, essentially doubling their costs.
This limitation is a major barrier to entry. If you want to avoid vendor lock-in of your data then you can’t use OneLake for storage. But what if Direct Lake offers such a massive improvement over using traditional methods that it’s worth the cost?
Performance on Larger Datasets
The benchmarks have been done, and they are quite concerning. At relatively low data volumes (under 100GB), Direct Lake performs slightly better than using a SQL warehouse endpoint on Databricks. Anything over this size results in a significant dropoff in performance, with Direct Lake having to fall back to DirectQuery mode. At very large data volumes of over 10TB, Direct Lake has so many failures as to be practically unusable; other users have noticed similar issues.
The Better Way to Integrate Power BI
However, there is a solution– you can easily connect to Power BI from Databricks using its Partner Connect or directly via Power BI itself. Using a Serverless SQL Warehouse provides near instant access to refreshed data for visualizations, and, as the benchmarks show, with extremely low latency. The data can be stored in ADLS or any other open cloud storage (even OneLake – but with the significant drawbacks previously mentioned), ideally utilizing Delta Lake for industry best price/performance.
This traditional method is simple and efficient. However, Databricks has made this process even easier, granting the ability to publish entire schemas into Power BI workspaces straight from the Catalog Explorer (Figure 1). This functionality extends to Tableau as well, removing the single option limitations of Fabric with OneLake. Instant reports can then be auto-generated based off of the newly published tables in the schema (Figure 2), with Databricks generating the PBI semantic models. This greatly enhances user experience by simplifying the integration process with Power BI.
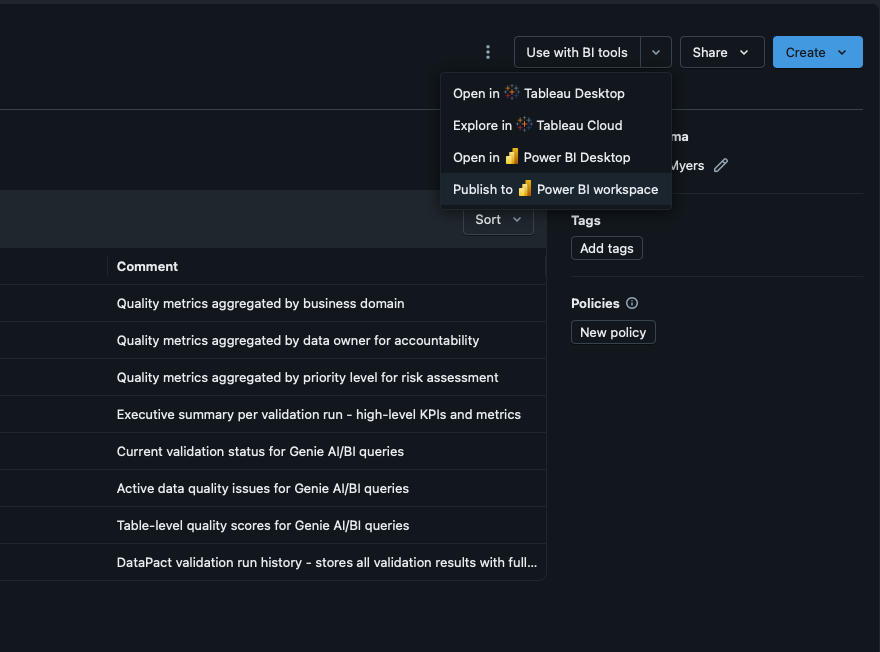

Figure 1: Publish to PowerBI from the Catalog Explorer
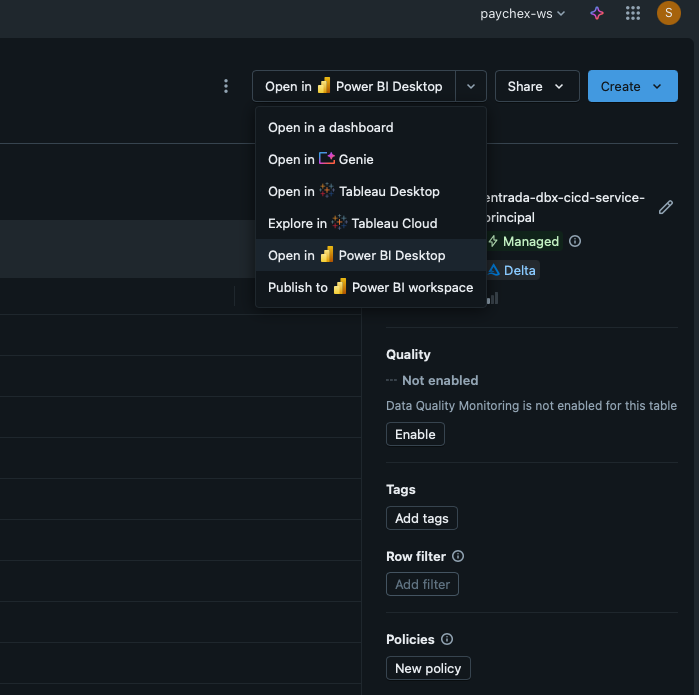
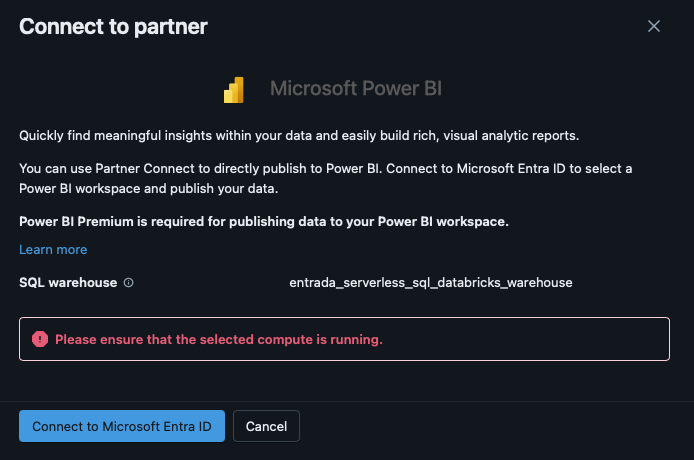
Figure 2: Auto Creation of Dashboards from Imported Schemas
Conclusion
In the realm of data engineering, the seamless integration of robust data processing platforms with powerful business intelligence tools is paramount. While Microsoft Fabric and Databricks both offer Power BI integration capabilities, a thorough analysis reveals that Databricks emerges as the superior choice.
In summary, while Microsoft Fabric and OneLake provide integrated solutions within the Azure ecosystem, their performance issues and the inherent vendor lock-in pose significant challenges. Databricks emerges as the better option for organizations that value flexibility, performance, and cost-efficiency in their data analytics operations. Its open architecture, superior performance, and user-centric features make it the ideal choice for organizations seeking to harness the full potential of their data. By leveraging Databricks’ robust capabilities, data engineers can seamlessly integrate their data processing pipelines with Power BI, unlocking valuable insights and driving data-driven decision-making.
In Part III of this blog series, we will be exploring what end to end Machine Learning means and comparing the features available within Microsoft Fabric and Databricks.
See Part I: The History of Big Data Platforms here.


