 Data Engineering
Data Engineering  Data Strategy + Governance
Data Strategy + Governance  Data Migrations
Data Migrations  Concierge + Support
Concierge + Support  Artificial Intelligence
Artificial Intelligence  Training + Enablement
Training + Enablement  Data Analytics + Insights
Data Analytics + Insights  Financial Services
Financial Services  Communications, Media + Entertainment
Communications, Media + Entertainment  Healthcare + Life Sciences
Healthcare + Life Sciences  Technology + Digital Natives
Technology + Digital Natives  Manufacturing + Automotive
Manufacturing + Automotive  Public Sector
Public Sector  Retail + Consumer Goods
Retail + Consumer Goods  Race to the Lakehouse
Race to the Lakehouse  AI + Data Maturity Assessment
AI + Data Maturity Assessment  Unity Catalog
Unity Catalog  Rapid GenAI
Rapid GenAI  Modern Data Connectivity
Modern Data Connectivity  Gatehouse Security
Gatehouse Security  Health Check
Health Check  Sample Use Case Library
Sample Use Case Library  Blog
Blog  Events
Events  About Us
About Us  Careers
Careers  Founding Team
Founding Team 
Introduction to RAG
Retrieval-Augmented Generation, or RAG, is an AI technology that blends the power of large language models (LLMs) with dynamic data retrieval capabilities from information stored in vector indexes in order to enhance the underlying LLM’s understanding of certain topics and to reduce hallucinations. RAG has its roots back to early efforts in the 1970’s with the development of question-answering systems and has more recently evolved significantly with advancements in AI algorithms and computational processing, culminating with much more sophisticated AI models.
Evolution and Current State of RAG
Initially conceptualized as systems that could answer questions within narrow domains, RAG systems have advanced into complex architectures capable of retrieving and integrating different information sources in real-time. This capability enhances the generation of responses that are contextually relevant and informed by ideally up-to-date external data. This helps to curtail two of the major limitations of the current top LLMs – not having access to the most recent information (with their understanding of current events not able to go past their latest training period) and hallucinations (when the AI invents an answer to a question with complete confidence when it doesn’t actually have a correct answer to give). Today, RAG is utilized across various domains, including customer support, healthcare, and financial services, to provide responses that are accurate, relevant, and timely.
How RAG Works
RAG works by interfacing a traditional LLM with a retrieval system. When a query is input, the system first retrieves relevant information from a range of vector indexes (vectorized for extremely fast lookup). This retrieved data is then fed into the LLM alongside the original query, enhancing the model’s ability to generate informed and accurate responses. As previously mentioned, this integration allows RAG to leverage the extensive learning capabilities of LLMs while mitigating their tendency for hallucinations or generating incorrect information based on its soon outdated training data.
Benefits of RAG
RAG offers several advantages over traditional, purely training based LLMs:
- Enhanced Accuracy: By integrating theoretically live data that can always be updated and enhanced by the users, RAG systems provide potentially more accurate and contextually relevant answers than an LLM not using a RAG system.
- Cost Efficiency: RAG can be cheaper and faster than retraining models, as it leverages existing data without the need for extra computational resources. This saves the hassle, effort, and cost of constantly retraining models with more recent data to keep its information current.
- User Trust: With responses that can cite current data, users gain increased trust in the AI’s outputs. Users can vet the RAG sources fed to the LLM to ensure its accuracy and trustworthiness – something that is much more certain than when an LLM is generating a response based on most likely unknown training data.
- Flexibility: Developers can fine-tune the sources of retrieved information, adapting the system to various needs and ensuring that sensitive data is handled appropriately. Since the data is not actually persisted to the LLM, unlike training data, it is easier to trust the AI model with sensitive information.
RAG in Practice
Companies have been applying RAG in innovative ways to enhance user interaction and operational efficiency. For example, AI-powered project management tools utilize RAG to analyze historical data and guide project planning processes. In content creation, RAG can accelerate the production of material that aligns with a brand’s standing by referencing previous successful outputs.
Future Directions
The future of RAG looks bright as it continues to integrate even more with various data ecosystems. Advances in modular RAG architectures are making these systems more flexible and powerful, allowing for customized setups that cater to specific operational needs. As these technologies evolve, it’s a safe prediction that RAG may become a standard Gen AI feature that drives more personalized, intelligent, and trustworthy interactions.
Integrating RAG with Generative AI Products
To utilize RAG effectively within your generative AI products, it is crucial to link your models to robust and authoritative data sources and to continuously update these sources to reflect the latest available information. If not done properly, RAG can actually be a hindrance rather than a boon to the accuracy of a model’s output. Tools like NVIDIA’s NeMo and Triton Inference Server provide a framework and platform to develop and deploy RAG applications efficiently.
LLMs Tuned for RAG
The latest cutting-edge LLMs have generally been putting more of an emphasis on RAG, particularly with the common case with them coming with a higher token limit. For instance, the new LLM Command R+, developed by Cohere, emphasizes RAG tasks.
Keys for RAG Optimized LLMs
The LLMs that are best suited for RAG have a few key shared commonalities:
- Quick data retrieval mechanisms
- Understanding of external data sources and when to reference them over/with pretrained data
- Contextual understanding
- Low latency in response times
Introduction to RAG on Databricks
Databricks, as common with them, has been at the forefront of integrating RAG into its platform, leveraging its lakehouse architecture to enhance the performance of RAG applications.
RAG Development Lifecycle on Databricks
The development lifecycle of RAG on Databricks encompasses several stages:
- Data Indexing: RAG applications start by indexing available data. This data can be structured or unstructured and is indexed to facilitate quick retrieval.
- Query and Retrieval: When a query is made, the system retrieves relevant information based on the context of the query.
- Response Generation: The retrieved data is then passed along with the query to an LLM which generates the response. This integration allows the model to provide answers that are both contextually aware and informationally accurate (assuming the data sources used are accurate and up to date, as previously discussed).
For the first step, Databricks makes it incredibly easy. With only a few clicks, you are able to create a vector index out of your tables:
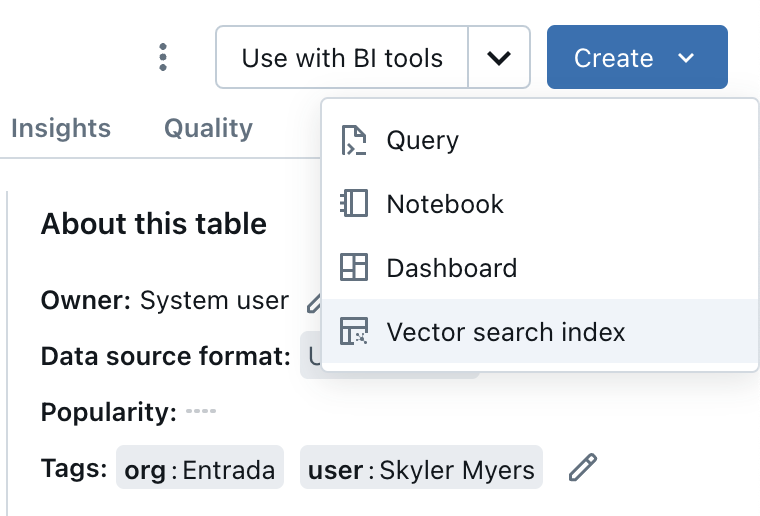
Databricks facilitates this lifecycle by offering robust data handling and processing capabilities with advanced AI tools to manage both the retrieval and generation aspects efficiently. The entire RAG/Gen AI lifecycle can be completed with Databricks, starting all the way back with the data ingestion, to data engineering, to AI management, as seen with its latest record breaking LLM, DBRX.
DBRX: Databricks’ LLM for Enhanced RAG
DBRX, Databricks’ latest LLM, is designed with a Mixture-of-Experts (MoE) architecture, which optimizes processing efficiency and makes it particularly suitable for tasks that benefit from RAG. It supports high-speed inference and can handle complex queries easily.
Effectiveness of DBRX in RAG
DBRX stands out due to its ability to integrate more seamlessly with Databricks’ data ecosystems. It is highly effective in RAG applications for several reasons:
- Speed and Efficiency: DBRX’s MoE architecture allows it to quickly process tokens and generate responses faster than many other models.
- Scalability: Its integration with Databricks’ cloud infrastructure allows it to scale dynamically based on demand.
- Data Integration: DBRX can effectively leverage real-time data updates, ensuring that the generated responses are not only accurate but also up-to-date. Another benefit of Databricks is that there is no separation of your AI models from your underlying data. The entire lifecycle is managed by Databricks.
Conclusion
The integration of RAG techniques with Databricks and the advanced features of DBRX creates a useful combination for developing sophisticated AI applications tailored to specific needs. This setup not only enhances the accuracy and relevance of responses provided by the AI systems but also ensures they are scalable and cost efficient. As RAG techniques continue to improve, their integration into platforms like Databricks will likely become more robust, pushing the boundaries of what’s possible in AI even further.


