 Data Engineering
Data Engineering  Data Strategy + Governance
Data Strategy + Governance  Data Migrations
Data Migrations  Concierge + Support
Concierge + Support  Artificial Intelligence
Artificial Intelligence  Training + Enablement
Training + Enablement  Data Analytics + Insights
Data Analytics + Insights  Financial Services
Financial Services  Communications, Media + Entertainment
Communications, Media + Entertainment  Healthcare + Life Sciences
Healthcare + Life Sciences  Technology + Digital Natives
Technology + Digital Natives  Manufacturing + Automotive
Manufacturing + Automotive  Public Sector
Public Sector  Retail + Consumer Goods
Retail + Consumer Goods  Race to the Lakehouse
Race to the Lakehouse  AI + Data Maturity Assessment
AI + Data Maturity Assessment  Unity Catalog
Unity Catalog  Rapid GenAI
Rapid GenAI  Modern Data Connectivity
Modern Data Connectivity  Gatehouse Security
Gatehouse Security  Health Check
Health Check  Sample Use Case Library
Sample Use Case Library  Blog
Blog  Events
Events  About Us
About Us  Careers
Careers  Founding Team
Founding Team 
Most ML projects don’t fail because the model is bad. They fail because the data feeding the model in production isn’t the same data the model was trained on.
I’ve spent the last several years architecting AI and Data platforms on the Databricks Lakehouse, leading teams through the messy middle between a promising notebook and a reliable production system. If there’s one component that consistently separates organizations achieving real AI maturity from those stuck in pilot purgatory, it’s the feature store.
This article dives into a collection of hard-won lessons from real deployments: what works, what quietly breaks, and how feature store-driven ML changes the economics of running ML at scale.
What Feature Store-Driven ML Actually Means
A feature store serves as not just a database for ML inputs but also a contract. It says: the feature your data scientist computed in a notebook on Tuesday is the exact same feature your model will see when serving a real-time request on Friday at 3 a.m.
In Databricks, this contract is enforced through the Databricks Feature Store, now deeply integrated with Unity Catalog and MLflow. It gives you:
- An offline store (Delta tables) for training and batch inference
- An online store for low-latency real-time serving
- A registry with lineage, governance, and discovery
- Feature Serving endpoints that abstract away the infrastructure
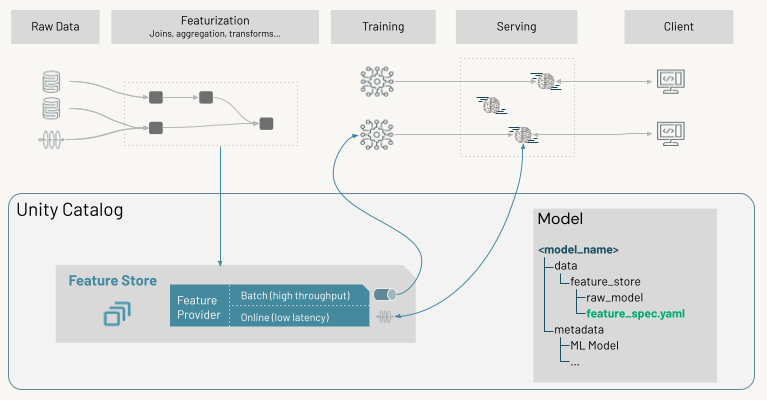
The end-to-end Databricks Feature Store workflow – features computed once, served twice. Unity Catalog tracks lineage from raw data through training to the model serving endpoint. Source: Databricks Documentation.
Source: Databricks Documentation
Sounds clean on a slide but reality is messier. Here’s what we’ve learned:
Lesson 1: Training-Serving Skew Is Still the Silent Killer
Industry research suggests training-serving skew affects roughly 40% of production ML models, and around 60% of ML projects fail due to data pipeline issues. In the field, we see this manifest as a “performance cliff”: the model looks like a hero in the notebook but fails to move the needle in production.
The mistake most teams make is viewing skew as a simple “data drift” issue. In reality, skew is the divergence of reality between two execution contexts. It usually falls into two buckets:
- Logic Skew: You use a Spark-based
Windowfunction for training features, but a different Python or SQL snippet in your real-time API. Even a tiny difference in how you handle nulls or rounding leads to the model receiving inputs it doesn’t recognize. - Temporal Skew (The “Hindsight” Trap): In training, you have the luxury of looking back at a user’s 30-day history with perfect clarity. In production, your streaming pipeline might be lagging by 10 minutes. If your model was trained on “perfect” data but serves on “delayed” data, its accuracy will crater.
Even teams that “have a feature store” still hit skew. Why? Adopting a feature store doesn’t automatically eliminate the structural problem: training and serving live in different execution contexts, with different latencies, different freshness expectations, and often different code paths. As we wrote in The Lost Art of Data Modeling in the Databricks Lakehouse, most production ML failures trace back to design-phase shortcuts – not modeling errors.
What works in practice:
- One definition, two destinations: Compute features once in Databricks using Feature Functions and write to both offline (Delta) and online stores from the same code path. Databricks handles the “compilation”: it runs as a batch job for your 100-million-row training set and automatically translates it into a low-latency lookup for your Model Serving endpoint.
- Use point-in-time joins: Data leakage is the most common form of “cheating” in ML. Databricks Feature Store’s
create_training_set()withTimestampLookupis non-negotiable for any model where time matters (which is most of them). It ensures that for every training row, the features provided are exactly what was known at that specific microsecond. Skip this and you’re leaking future data into training.
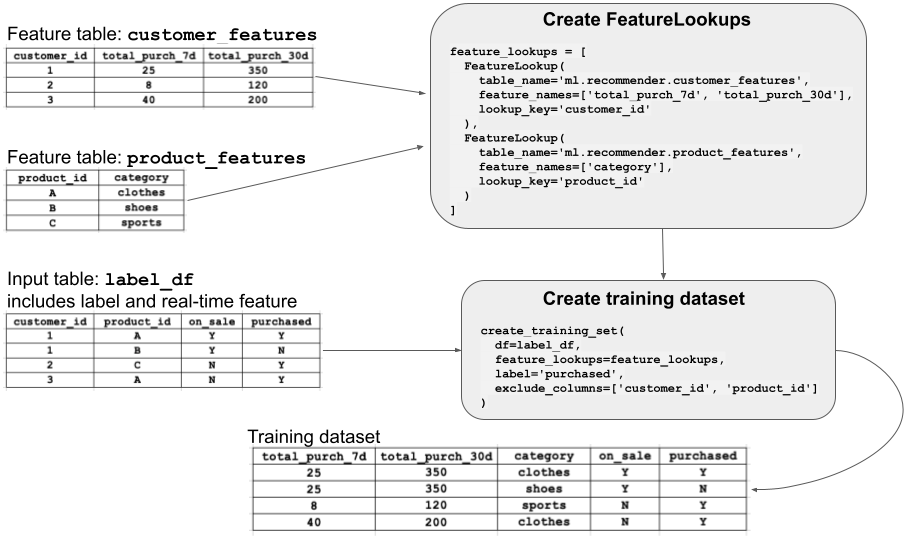
FeatureLookup joins multiple feature tables to label data via primary keys, producing a leakage-free training set through create_training_set. This is the architectural enforcement of training-serving parity. Source: Databricks Documentation.
- Inference logging: The “silent” part of the silent killer is that skew often goes unnoticed until the business KPIs tank. Feature Serving endpoints allow for logging the augmented DataFrame (actual feature values served) into inference tables. Use this. By comparing these back to your training distributions, you move from “guessing why accuracy dropped” to “knowing exactly which feature drifted.”
Teams that treat feature parity as a tested invariant, rather than a hope, are the ones that actually stay in production.
Lesson 2: Governance Isn’t Bureaucracy – It’s Speed
A common pushback I hear: “Unity Catalog and feature lineage will slow my team down.” The opposite is actually true at scale. The teams that move fastest in production are the ones who invested in governance early. Here’s why.
Without a registry, a credit-risk feature like customer_30d_avg_balance gets reimplemented three times by three teams, with subtle differences in how they handle nulls, weekends, and currency conversion. Each model is “correct” in isolation. Together, they’re a compliance disaster. This is exactly the gap we tackled when designing our next-generation governance experience for Databricks – turning Unity Catalog into a true governance operating surface, not just a metadata layer.
Our approach with clients:
- Treat features as products. Every feature table has an owner, a description, freshness SLAs, and quality checks (Lakehouse Monitoring or DLT expectations).
- Enforce naming conventions at the catalog/schema level –
entity_grain_metric_window(e.g.,customer_daily_revenue_30d). - Version through code, not copies. Feature definitions live in Git, deployed via Declarative Automation Bundles (DABs). That way, no one creates a feature table in a notebook and forgets about it.
This is what separates ML professionals from ML enthusiasts. It’s the difference between a model registry full of orphaned artifacts and a platform where new use cases compound on prior investment.
Lesson 3: Online Stores Are Where Architecture Value is Realized
Most teams underestimate the operational complexity of online serving. A model that runs in 200ms during testing can degrade to 3 seconds in production once you account for cold starts, feature lookups across multiple tables, and network hops.
A few patterns that have repeatedly saved deployments:
- Co-locate features by access pattern. If a model needs 12 features at inference, don’t fan out to 12 different online tables. Materialize a serving-optimized table that mirrors the model’s actual lookup signature.
- Use Feature & Function Serving. On-demand computations (currency conversion, age from birthdate, simple ratios) shouldn’t be precomputed and stored, they should be computed at request time inside Databricks Feature Serving. Less storage, fresher data, less drift surface area.
- Right-size the TTL. Online stores aren’t free. Features that change daily don’t need second-level freshness. The same logic applies to compute itself – see our Databricks serverless workload shape playbook for how we decide which parts of an ML pipeline should run serverless and which shouldn’t. We often save 40-60% on serving costs simply by aligning TTLs and compute shape to actual business cadence.
Lesson 4: Reuse Is the Real ROI Driver
Executives ask me what the ROI of a feature store looks like. The honest answer: it’s not the first model. It’s the fifth, tenth, twentieth, etc.
The first ML use case absorbs the platform cost. Every subsequent one inherits it. When a churn-prediction team can pull customer_engagement_score_7d from the registry instead of rebuilding it from raw events, you’ve cut weeks out of the development cycle. Multiply that across a portfolio of 20+ models and the math gets compelling fast.
This is where partnering with a Databricks-native team accelerates outcomes – the architectural decisions made in the first three months determine whether reuse ever happens or whether every team rebuilds from scratch. As a Databricks Ventures portfolio company, we’ve seen this play out across numerous engagements.
Lesson 5: Start Smaller Than You Think
The biggest mistake I see is treating feature store adoption as a “platform project” – six months of architecture before a single model ships.
Don’t.
Start with one high-value use case. Build three to five well-governed features. Ship it to production to measure skew, latency, and reuse. Then expand.
Incremental adoption reduces risk, builds organizational muscle, and, critically, gives you real data about your team’s actual constraints rather than theoretical ones. You can read more about how we apply this across AI and ML engagements.
What Good Looks Like
When a feature store-driven ML practice is working, you’ll notice:
- New models reach production in weeks, not quarters
- Training-serving skew incidents drop sharply because parity is enforced by architecture, not discipline
- Data scientists spend more time on modeling, less on data plumbing
- Compliance and audit conversations get shorter, because lineage is built-in
- The marginal cost of the next ML use case approaches zero
That’s what AI maturity actually looks like at the platform layer.
Final Thought
Feature stores are a way of making the contract between data engineering and ML explicit, testable, and reusable. They are not a silver bullet. On Databricks, the integration with Unity Catalog, MLflow, and Lakehouse Monitoring makes this contract enforceable in a way that was genuinely difficult to achieve five years ago.
The organizations winning with AI right now aren’t the ones with the most sophisticated models. They’re the ones who got the boring infrastructure right, including feature stores which sit squarely in the middle of that infrastructure.
If you’re building or scaling ML on Databricks and want to compare notes on what’s working, our team at Entrada has helped clients across financial services, retail, and industrial sectors put these lessons into practice. Drop us a line at info@entrada.ai – we’d be glad to talk.


